


![图片[1]-AI读不懂文档结构?计算所重构Agentic RAG文档推理能力-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/03/20260317010215967-1773680535-b3cfccfcf7de71b32b39ce618e32cf50.png)
新智元报道
【新智元导读】DeepRead让AI像人一样阅读文档:利用OCR识别章节结构,先精准定位相关段落,再完整读取上下文,避免碎片化检索。实验显示,其长文档问答准确率提升17%,能自动跳过冗余信息,精准提取财报、论文等复杂内容,无需额外知识图谱,轻量高效。
大语言模型的工具使用能力正推动RAG从静态的一次性检索,向自主、多轮的证据获取进化,Agentic RAG已成为解决复杂问答任务的核心方向。
但现有主流Agentic Search框架普遍存在一个关键痛点——结构盲:它们将长文档视为无差别的扁平文本块,忽略了文档原生的层级组织(如章节、段落)和顺序逻辑,导致检索碎片化、证据遗漏、冗余操作等问题频发。
比如说,人类查询「ACL论文投稿要求」时,会先翻阅目录找到「投稿指南」章节,再逐段精读关键信息。
但传统Agentic Search(如Search-o1)却只能通过不断给出新的query反复检索,可能遗漏「页码限制」「格式要求」等未被关键词覆盖的内容,还会重复获取已浏览过的片段。
![图片[2]-AI读不懂文档结构?计算所重构Agentic RAG文档推理能力-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/03/20260317010217947-1773680537-fd5d93798681e68449a2dbc7b3514f99.png)
这种「结构盲」带来三大问题:
证据碎片化:将文档拆分为固定大小的文本块,破坏语义连贯性,迫使智能体拼接零散片段;
检索冗余:缺乏全局结构认知,反复检索同类信息,浪费计算资源;
信息遗漏:依赖关键词匹配,无法捕获章节内隐含的相关信息。
而现代OCR技术已能精准提取文档的层级结构和阅读顺序,这为解决「结构盲」提供了基础——让智能体学会利用这些原生结构,而非忽视它们。
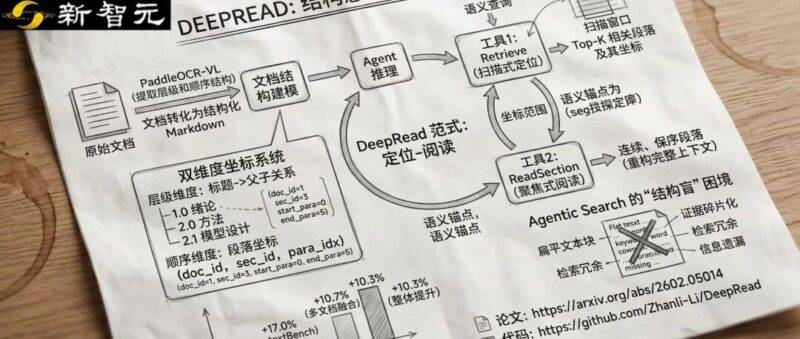
中国科学院计算技术研究所团队提出的DeepRead,核心创新是将文档结构转化为智能体可理解、可操作的坐标系统,通过两大工具协同实现类人推理,整体框架参考下图。
![图片[3]-AI读不懂文档结构?计算所重构Agentic RAG文档推理能力-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/03/20260317010220284-1773680540-6d542c444d3f825facfffb59ac0aacde.png)
论文:https://arxiv.org/abs/2602.05014
代码:https://github.com/Zhanli-Li/DeepRead
![图片[4]-AI读不懂文档结构?计算所重构Agentic RAG文档推理能力-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/03/20260317010223150-1773680543-5413a3c5a5b89751bba22326e2d946cc.png)
文档结构建模:给每个段落分配「坐标」
DeepRead首先通过OCR工具将原始文档转化为结构化Markdown格式,构建双维度结构模型:
层级维度:区分标题(如章节)和内容段落,记录标题的父子关系(如「2.方法」包含「2.1模型设计」);
顺序维度:给每个段落分配唯一坐标(doc_id, sec_id, para_idx),即「文档ID-章节ID-段落索引」,让每个文本片段都有明确的位置标识。
同时,DeepRead会将轻量化的目录(TOC)注入系统提示,让智能体掌握全局结构,无需加载全量文档内容,平衡上下文开销与结构感知能力。
两大核心工具:Retrieve与ReadSection的协同
DeepRead为智能体配备两个互补工具,模拟人类「快速定位+深度阅读」的行为:
Retrieve(扫描式定位):接收语义查询,返回Top-K相关段落及其坐标,同时支持「扫描窗口」(在召回的段落加上前后各1段),模拟人类快速浏览上下文的行为;
ReadSection(聚焦式阅读):接收坐标范围(如doc_id=1, sec_id=3, start_para=0, end_para=5),返回该范围内的连续、保序段落,重构完整语义上下文,彻底解决碎片化问题。
两者形成闭环:Retrieve负责「找方向」,快速锁定相关章节;ReadSection负责「深挖掘」,获取完整证据,避免关键词检索的局限性。
无需手动编码规则或是特定指令,DeepRead可自主进化出类人推理策略:先通过Retrieve获取结构锚点,再调用ReadSection精读相关章节。实验显示,90%以上的查询会遵循这一范式,且工具调用比例会自适应任务特性——ContextBench(长文档推理)更依赖ReadSection,FinanceBench(金融数据提取)更依赖Retrieve。
![图片[5]-AI读不懂文档结构?计算所重构Agentic RAG文档推理能力-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/03/20260317010225102-1773680545-d420b366e8dcedf01f79c6b499029f49.png)
![图片[6]-AI读不懂文档结构?计算所重构Agentic RAG文档推理能力-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/05/1748005937-e247941b79065a0391afc9648900dec5.png)
研究人员在四大基准数据集(涵盖单文档/合成多文档数据集)上验证了DeepRead的效果,核心结果参考下表
![图片[7]-AI读不懂文档结构?计算所重构Agentic RAG文档推理能力-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/03/20260317010228150-1773680548-ad55981346bebf0593224e79526b873b-scaled.png)
关键亮点包括:
长文档推理突破:在需长距离依赖的ContextBench上,DeepRead准确率从74.5%提升至91.5%,提升幅度达17.0%,验证了结构感知对长文档的价值;
多文档融合优势:在基于QASPER(学术论文问答)和SyllabusQA(课程大纲对比)合成的多文档数据集上表现优越,分别提升7.7%和13.8%,证明结构感知能有效跨文档整合证据;
鲁棒性验证:通过DeepSeek-V3.2、GLM-4.7、Qwen3-235B三大独立法官评估,结果一致率达88.58%,确保提升并非偶然。
![图片[8]-AI读不懂文档结构?计算所重构Agentic RAG文档推理能力-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/03/20260317010231212-1773680551-5fc73a993844f4e967967be32ed23377.png)
值得注意的是,DeepRead的优势并非来自「更多的检索片段」——即使Search-o1允许检索更多文本块,仍无法弥补结构缺失的差距;而盲目扩展上下文(expand)可能会降低DeepRead在部分任务上的性能,因为结构化阅读已能提供足够连贯的证据,冗余文本只会引入噪声。
案例直观感受:从「关键词拼凑」到「章节精读」
以FinanceBench中的亚马逊营收计算任务为例:
传统Search-o1风格的Agentic Search需反复检索「2016营收」「2017净销售额」等关键词,可能混淆「预估数据」与「实际财报数据」;
DeepRead则先通过Retrieve定位到「合并利润表」章节,再用ReadSection读取完整表格,精准提取2016年135987百万美元、2017年177866百万美元的净销售额,计算出30.8%的同比增长率。
DeepRead的核心价值在于:挖掘文档原生结构先验,用轻量坐标系统和协同工具,实现了Agentic RAG的结构感知升级。
相比构建复杂知识图谱的方案,DeepRead无需额外结构化成本,仅通过OCR解析和工具设计,就在长文档、多文档任务上实现显著提升,兼具实用性和效率。
![图片[10]-AI读不懂文档结构?计算所重构Agentic RAG文档推理能力-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/10/c79a0da0a19ad66c831baa7a391a0e27.jpeg)
![图片[11]-AI读不懂文档结构?计算所重构Agentic RAG文档推理能力-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/01/20260101203539201-1767270939-a915c63cfe6f7cc68cc454f351b00750.jpeg)
<原文链接:https://mp.weixin.qq.com/s/BhvUQgREp4NOvb6axiWXiQ














暂无评论内容