


3月6日,腾讯混元发布了一篇名为《HY-WU (Part I): An Extensible Functional Neural Memory Framework and An Instantiation in Text-Guided Image Editing》的技术报告,提出了一种崭新的功能性记忆(functional neural memory)范式(weight unleashing),在模型推理时实时生成个性化参数,由此对不同任务/分布/样本进行个性化适应。
腾讯混元团队将HY-WU (混元无相)应用在各大开源图形编辑基模上,有效扩充了基模的功能性记忆,在图形编辑任务上普遍取得了更好的内容理解、指令遵循和生成质量。与此同时,该范式的数据效率、训练效率和推理速度也做到了真正的实用性与创新性并重。
![图片[1]-新范式!腾讯混元提出HY-WU(无相),让模型实时生成参数“换脑”-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/03/20260309002244170-1772986964-097bd9dcc8dbd4e0cdc54753e1bdc392.gif)
让我们看看技术报告的具体内容。
Blog: https://tencent-hy-wu.github.io
GitHub: https://github.com/Tencent-Hunyuan/HY-WU
基模学习的两大挑战:学了新的,忘了旧的,千人千面的个性化问题
在各个领域的基模(Foundation Model)中,普遍存在着两个互为犄角的挑战:
1、“灾难性遗忘”与持续学习的冲突: 已经训练好的基模在面对新数据、新任务时,通常需要通过微调(Fine-tuning)进行重新学习来取得最佳表现。
然而,传统的适配模式往往是“覆盖式”的,即在共享权重的同一个参数点上进行反复擦写 。这种做法极易导致新旧知识的梯度冲突,损害模型已有的基础能力,导致“学了新的,忘了旧的”。这点在functional memory上尤其突出,对于映射的学习无法被外部存储替代,神经元的改写会导致以往拟合的映射发生变化。
2、“跷跷板效应”与个性化的权衡: 面对不同用户、不同领域的多样化需求,现有模型往往陷入“参数空间的不可能三角”。例如,在大型语言模型(LLM)中,同参数量模型在强化了严密的编程逻辑后,往往在发散性思维或特定风格的生成上表现出‘顾此失彼’的问题;在图像编辑中,增强“去噪”能力可能会损害模型对“艺术风格”的保留 。这种“千人千面”的个性化需求,在参数空间内往往对应着相互分离甚至冲突的“可行域”,强行用一个共享参数去拟合所有需求,最终只能得到各方妥协的平庸结果。虽然业界尝试通过 MoE (混合专家模型) 或海量数据对齐来缓解,但本质上仍是在有限的参数空间内做‘存量博弈’,难以跳出‘性能跷跷板’的困境。HY-WU 范式正是要打破这种静态权重的束缚,在不损失基模能力的前提下完成个性化适应。
1.1 现有解法的局限性:静态权重范式的天花板
为了解决上述问题,目前主流的解法包括:
1、参数高效微调(PEFT,如 LoRA): 虽降低了训练成本,但本质上仍属于“静态参数记忆” 。一旦适配完成,推理时所有样本都共用同一组固定的参数更新。这种“一刀切”的模式在处理高度异构或持续进化的任务时,依然无法逃脱参数冲突和过拟合的困境 。
2、上下文记忆(RAG / 检索增强): 通过外部存储注入背景信息,但这只能改变模型“看到了什么”,而无法改变模型“如何处理信息” 。当任务核心在于处理规则(如特定的图像变换逻辑)而非缺失事实时,仅仅依靠增加上下文无法从根本上改变模型的变换算子(Operator)。
3、独立LoRA集群:为每个任务训练独立的 LoRA 适配器。这虽然避免了冲突,但会导致存储开销随任务量爆炸式增长,且不同模块间难以实现知识迁移,泛化能力受限 。
4、MoE(混合专家模型) :混合多个专家针对不同domain进行路由学习和推理。能改善拟合多种分布的问题,但对于灾难性遗忘和性能跷跷板的困境不能从根源上解决。(哪怕是 GPT-5.3 还是 Claude 4.6,都在‘编程强化’后陷入了某种程度的‘功能偏科’:编程逻辑的极致提升,同参数量下伴随着创造性的流失或常识直觉的僵化。)
![图片[2]-新范式!腾讯混元提出HY-WU(无相),让模型实时生成参数“换脑”-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/03/20260309002249610-1772986969-68b3736345b4ccedefb3b7cfc0bd37e1.png)
图:静态记忆,上下文记忆和混元团队提出的功能性记忆的对比。
1.2 HY-WU的方案:从“静态参数记忆”到“功能性记忆”
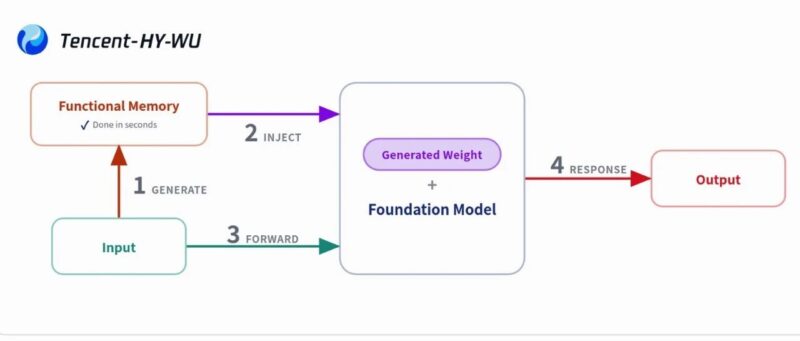
针对这些痛点,混元团队提出了HY-WU (Weight Unleashing)范式。团队指出,适配问题的核心不在于优化算法,而在于“记忆接口”(Memory Interface)的设计。
传统的适配(如 SFT 或 LoRA)本质上是静态参数记忆,它试图将所有新知识压缩进参数空间的一个“单一特征点”中,这在处理异构任务时会导致结构性的脆弱。
HY-WU 则引入了功能性记忆(Functional Memory)。该范式不再追求寻找一个通用的固定参数点,而是学习一个参数生成器。它将适配过程看作是根据输入条件实时合成特定算子(Operator)的过程。这种“记忆即神经网络”的正式化表达,使得模型能够根据不同实例在权重空间内进行动态路由(Routing),从而避免了在共享参数上的反复擦写与冲突。
两种问题,一个对策:Functional Neural Memory在图像编辑任务上的的参数生成实现
混元团队选择用“文本引导的图像编辑”(Text-Guided Image Editing)作为 HY-WU的首个压力测试,因为图像编辑天然地暴露了静态权重的局限性:
1、目标互斥: “修复老照片”和“照片做旧”在参数空间里是完全不同的变换方向。如果用同一个静态适配器(如 LoRA)强行学习,模型会陷入“两头不到岸”的平庸折中 。
2、样本敏感: 同样的“风格化”指令,在猫的图片和山水的图片上,需要执行的像素变换截然不同 。
2.1 核心范式:从“存数据”到“存算子映射”
HY-WU 提出了一个开创性的认知:功能性记忆不该是固定的知识点,而应该具有动态的条件映射。
该框架引入了一个基于 Transformer 架构的参数生成器。它不像传统 LoRA 那样去学习一组固定的权重,而是学习如何生成针对特定实例的算子权重 :
1. 实时感知: 模型首先提取当前输入图片和编辑指令的“混合条件特征”。
2. 即时合成: 生成器根据这些特征,在推理时实时生成出一组针对当前样本的最优 LoRA 参数 。这个过程在百亿参数的图像编辑基模上也仅需几秒。
3. 动态挂载: 这一组定制化的参数被立即注入到冻结的基模(Frozen Backbone)中,完成特定的编辑变换。
![图片[3]-新范式!腾讯混元提出HY-WU(无相),让模型实时生成参数“换脑”-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/03/20260309002251947-1772986971-09d025a30735359112438b147e2b5ce6-scaled.png)
图:HY-WU流水线概览
而和以往大部分参数生成工作不同,HY-WU采取了端到端的训练,完全不需要收集模型checkpoint来训练。
![图片[4]-新范式!腾讯混元提出HY-WU(无相),让模型实时生成参数“换脑”-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/03/20260309002253817-1772986973-4c308821c23d5bb9b2a2af5e76891033.png)
图:HY-WU模型架构Neural Network Transformer的细节
针对billion-scale的参数生成,HY-WU设计了Factorized self-attention来优化计算,大大降低了复杂度。其模型结构如上图所示。
2.2 功能性记忆:学习“条件更新族”而非“孤立算子”
为了实现动态路由,混元团队提出了条件更新族(Conditional Family of Updates)的概念。在功能性记忆的视角下,适配的目标不再是“找到一个特定的更新”,而是“学习一个从条件到参数更新的映射”。
通过这种方式,HY-WU 诱导出一个结构化的参数流形。图像编辑的分析实验证明,生成的参数在权重空间中呈现出精妙的语义结构:功能相似的编辑操作(如动物形变、风格迁移)会自动聚集在参数空间的邻近区域。这种权重空间的几何一致性表明,功能性记忆成功捕捉到了任务背后的变换规则。这使得系统在面对冲突目标时,可以通过路由到更新族的不同区域来化解干涉,而非被迫进行性能妥协。
![图片[5]-新范式!腾讯混元提出HY-WU(无相),让模型实时生成参数“换脑”-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/03/20260309002255964-1772986975-738ba1e719c6fe05025f611112e5ca8e.png)
图:HY-WU参数空间的Semantic Map
2.3 实用性考量
HY-WU在实用性方面做了充分考量。它不需要像传统 Hypernetwork 那样依赖预先收集的大量微调权重(Checkpoints),也不用在部署时存储大量LoRA权重来随时加载。HY-WU采取端到端训练和生成,作为分离挂载的功能性记忆,不仅保证了生成的参数足够“个性化”,更让整个系统具备了极高的训练效率和工程部署的灵活性和可扩展性。
图像编辑任务上的优秀表现
研究人员将HY-WU应用于HY-Image-3.0-Instruct —— 这是一个拥有 800 亿(80B)参数的原生多模态基座模型(其中激活参数为 13B)。
为了实现精准的图像编辑,该团队引入了一个拥有81.1亿参数的 Transformer 参数生成器。该网络能为所有线性模块生成 7.2 亿参数的Rank-16 LoRA权重,从而确保模型在处理复杂的编辑指令时具备极高的灵活性与准确度。
3.1 HY-WU个性化能力展示
HY-WU在社交、游戏和广告等场景展现出较好应用效果,下面展示了与其他模型在个性化场景下的对比:
![图片[6]-新范式!腾讯混元提出HY-WU(无相),让模型实时生成参数“换脑”-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/03/20260309002257757-1772986977-ee8849ee8bd716883bdfebb9d8820f6a.png)
![图片[7]-新范式!腾讯混元提出HY-WU(无相),让模型实时生成参数“换脑”-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/03/20260309002259528-1772986979-002b57a6a7acd80e32de59b6e2fcfa05.png)
![图片[8]-新范式!腾讯混元提出HY-WU(无相),让模型实时生成参数“换脑”-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/03/20260309002303848-1772986983-abbd60bd1e41a2b3fc17cf74076e86c9.png)
图:HY-WU与Seedream 4.5,GPT Image 1.5,Nano Banana 2的对比。在换装,试穿和换脸的个性化场景中,HY-WU均表现出更强的特征一致性,充分展现了其适配能力,为用户提供了更多想象空间。
3.2 严苛评测:覆盖 60 余种编辑任务
为了验证 HY-WU 的实战能力,研究团队构建了一个全面的评测,涵盖了单图和多图编辑两大赛道。该测试包含 346 组单图和 64 组多图编辑对,涉及 60 个细分编辑子任务,支持中英双语指令,覆盖了广泛的现实场景。评测对象涵盖了目前市面上最强的一线模型,包括 OpenAI 的GPT-Image-1.5、Google 的Nano Banana Pro以及Seedream, FLUX.2、Qwen-Image-Edit 等知名开源项目。
3.3 人类评价:比肩闭源旗舰
在代表用户真实感知的GSB(Good/Same/Bad)人类评价中,HY-WU 表现惊艳。数据显示,HY-WU 的表现显著优于所有主流开源模型。在与顶级闭源模型的对比中,HY-WU 依然保持了极强的竞争优势,其感官质量仅略逊于 Google 的 Nano Banana。
![图片[9]-新范式!腾讯混元提出HY-WU(无相),让模型实时生成参数“换脑”-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/03/20260309002304552-1772986984-4fa289bd3dbd34ccb2a40ca22cc9992d.png)
图:GSB评测结果
3.4 自动化榜单:达到领先水平
除了人类评价,HY-WU 在多个权威自动化测试集上也取得了亮眼的成绩:
1、GEdit-Bench:HY-WU 树立了开源模型的新标杆。在中文测试(GEdit-Bench-CN)中,它在语义一致性、整体评分和感知质量三大维度上均斩获开源模型第一。在英文测试中,其语义一致性同样位居榜首。值得注意的是,HY-WU 在这六项核心指标上好于闭源模型 Seedream 4.5 和 Nano-Banana-Pro。
![图片[10]-新范式!腾讯混元提出HY-WU(无相),让模型实时生成参数“换脑”-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/03/20260309002306866-1772986986-533610a70e26be895731902a667cfb20.png)
2、ImgEdit-Bench:在9项细分编辑任务中,HY-WU在开源模型中夺得了 5 项第一和1项第二。其4.05的总分在所有公开模型中排名第二,与闭源霸主GPT Image 1.5 的差距仅为0.11分。
![图片[11]-新范式!腾讯混元提出HY-WU(无相),让模型实时生成参数“换脑”-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/03/20260309002308931-1772986988-5d41ad10de88fc51e5481e0319b75a57.png)
3.5 扩展性研究:普适性与“规模法则”
研究团队进一步探讨了 HY-WU 的普适性。实验证明,该框架不仅适用于原生多模态模型,在传统的MMDiT架构(如 Qwen-Image-Edit-2509)上同样能带来显著的性能提升。
此外,HY-WU 遵循显著的规模法则(Scaling Law):
1、模型容量:随着 Transformer 深度从 2B 增加到 7B,性能持续增强。
2、权重规模:通过增加 LoRA 的秩(Rank),从 0.12B 扩展至 0.47B 参数,模型表现也呈现出清晰的正相关增长。
新范式的新展望:迈向“记忆分离”与“功能模块化”的智能架构
HY-WU技术报告的末尾,混元团队并未止步于图像编辑,而是描绘了一幅以“功能性神经记忆(Functional Neural Memory)”为核心的未来 AI 路线图, 传达了他们对大模型架构范式探索前沿的思考。
R1: 检索记忆与功能记忆的协同
存储事实知识的“检索记忆”与存储变换逻辑的“功能性记忆(HY-WU)”从目的和方式上是互补而非替代。究竟什么情况下检索记忆是不够的,而什么情况下功能性记忆构成了互补,是下一步需要实验性验证的重要问题。混元团队建议在需要事实性和样例时考虑检索记忆,而需要变换规则和过程控制时考虑功能性记忆。功能性记忆提供了operator算子需要发生变化时的灵活性。
R2: 在线持续学习协议 (Online & Continual Protocols)
长远来看,功能性记忆的愿景在于:让新行为对应于参数更新族(Update Family)上的新区域,而非对共享参数点的不可逆覆盖。虽然 Part I 在机制上通过冲突控制研究和对齐消融实验验证了这一方案的可行性,但尚未评估真正的“在线持续学习”。
混元团队提出,下一步的目标是利用功能性记忆作为算子级工作记忆(Operator-valued Working Memory),定义一种在线协议。通过这种协议,系统在处理顺序到达的新目标时,能够将新技能“写入”更新家族的未开发区域,从而在提升新任务表现的同时,从根本上解决灾难性遗忘问题。
R3: 架构容量的重新分配 (Capacity Reallocation)
“记忆优先”设计的核心假说在于:规模化(Scaling)不应仅仅意味着增加主干网络的体量。混元团队大胆推测:将主干模型与功能性记忆模块联合规模化,比单纯扩展单体主干模型更具计算和数据效率。
这种直觉源于结构上的重构:单体规模化必须将长尾和冲突的目标“摊销”到一个单一的参数点上,这必然导致妥协与干扰;而功能性记忆分配的是“条件算子容量”,使得罕见或冲突的行为无需被强行固化在共享权重中。
团队在文中提出了四个探索维度,目标在于在于定量化分析:当主干网络参数达到饱和时,通过增加功能性记忆容量,如何进一步提升模型的可控性、冲突鲁棒性及个性化能力。
R4: 跨模态的通用性 (Cross-Modality Universality)
HY-WU (Part I) 以图像编辑作为概念验证,但功能性神经记忆的范式在本质上是通用的。核心挑战在于:如何在不同的信号空间(如视频、音频、3D 或多模态智能体)中,利用统一的参数流形逻辑来实现一致的指令遵循。
视频生成中的时间相干性:视频模型通常在时间注意力层(Temporal Attention)面临巨大的平衡压力。通过引入功能性记忆,模型可以为特定的动作序列生成动态的算子偏移,从而在不破坏基础生成能力的前提下,增强动作的幅度与准确性。
多模态对齐:在视觉问答或交互式任务中,主干网络往往需要处理高度异构的输入。功能性记忆可以根据输入模态的比例,实时调节跨模态融合层的参数权重,实现更灵活的感知对齐。
R5: 长时一致性与身份记忆 (Identity & Long-horizon Consistency)
在长序列生成或复杂的 Agent 交互中,保持身份(Identity)的一致性是一个长期存在的瓶颈。传统的微调方式往往会导致全局权重的偏移,而 R5 展望通过功能性记忆来专门存储“身份算子”。团队提出如下探索方向:
身份算子化: 可以为特定角色或对象维护专门的参数生成逻辑。当模型识别到特定实体时,生成器会即时合成一套专属的参数约束,确保该角色在跨场景、长时跨度的生成中,其核心特征(如面部细节、材质纹理)始终保持稳定,不随背景或动作的变换而发生漂移。
长时一致性: 这种“记忆分离”架构允许模型在处理长视频或多轮交互时,通过动态挂载不同的功能模块来维持逻辑连贯性,实现真正的长程受控生成。
R6: 硬件感知的部署优化 (Hardware-Aware Deployment)
将适配压力从“静态权重”转移到“动态参数生成”,对推理侧提出了新的系统性挑战。R6 聚焦于如何让这种新范式在实际生产环境中具备极高的运行效率。
定制化内核 (Custom Kernels): 动态生成的参数(如不同实例对应的 LoRA 更新)往往会导致显存访问模式的碎片化。我们需要开发硬件感知的优化方案,例如针对动态 LoRA 权重设计的定制化算子融合技术,以减少参数切换带来的开销。
高效推理引擎: 通过与 FlashInfer 等高性能推理引擎结合,优化生成器与主干网络之间的协作效率。
端侧实用性: R6 的终极目标是降低参数生成的延迟与功耗,使得 HY-WU 这种“千人千面”的个性化实时适配,能够在手机、AI PC 等端侧设备上真正落地。
“HY-WU (Part I) 仅仅是一个开始。通过将参数‘释放’(Weight Unleashing),HY-WU正在赋予 AI模型一种前所未有的灵活性。混元团队相信这是更强的智能的必要一环。
<原文链接:https://mp.weixin.qq.com/s/obFDE56Ramxn_L8-2VFAaw













暂无评论内容