



金磊 发自 凹非寺
量子位 | 公众号 QbitAI
不得了,机器人现在开始学会脑补未来了。
这就是蚂蚁灵波又又又又(连续第4天)开源的狠活儿——
全球首个用于通用机器人控制的因果视频-动作世界模型,LingBot-VA。
![图片[1]-大事不好!机器人学会预测未来了-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/01/20260131013006682-1769794206-d9f9e69e08736964fe127f346860bb85.png)
怎么个脑补法?
简单来说啊,以前的机器人(尤其是基于VLA的)干活儿,主打一个条件反射:眼睛看到什么,手立刻就动一下。
这叫“观察-反应”模式。
但LingBot-VA就不一样了,它通过自回归视频预测打破了这种思考方式,在动手之前,脑子里先把未来几秒的画面推演出来。
说实话,用想象力做决策,在机器人控制这块还是相当新鲜的。
但这不是LingBot-VA唯一的亮点,还包括:
记忆不丢失:做长序列任务(比如做早餐)时,它会记得自己刚才干了什么,状态感知极强。 高效泛化:只要给几十个演示样本,它就能适应新任务;换个机器人本体,也能hold住。
![图片[2]-大事不好!机器人学会预测未来了-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/01/20260131013009392-1769794209-a715e22a944548888ea53940dd8f70e2.png)
因此在LingBot-VA的加持下,像清洗细小的透明试管这种高精度任务,机器人已经是可以轻松拿捏:
正如我们刚才提到的,今天是蚂蚁灵波连续第四天开源。
如果说前几天的开源是给机器人加强了眼睛(LingBot-Depth)、大脑(LingBot-VLA)和世界模拟器(LingBot-World),那么今天的LingBot-VA,就是让这具躯壳真正拥有了灵魂——
一个行动中的世界模型,让想象真正落到执行层面。
如此一来,通用机器人的天花板,算是被蚂蚁灵波往上顶了一截。
正如网友所述:
从预测到执行;说实话这是巨大的飞跃。
![图片[3]-大事不好!机器人学会预测未来了-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/01/20260131013013873-1769794213-ee9fb6ad6d3a59b53486880e8acc6729.png)
让想象力先行一步
LingBot-VA在架构设计上选择了一条更进一步的路径。
在传统的VLA(视觉-语言-动作)范式中,模型通常会将视觉理解、物理变化推理、低层动作控制这三项复杂任务放在同一个神经网络中处理,这在学术界被称为表征缠绕(Representation Entanglement)。
为了追求更高的样本效率和更强的泛化能力,LingBot-VA选择把这团乱麻解开,提出了一套全新的解题思路:先想象世界,再反推动作。
为了实现这个想法,蚂蚁灵波团队采用了一个两步走的策略:
视频世界模型:先预测未来的视觉状态(接下来会发生什么)。 逆向动力学(Inverse Dynamics):基于视觉的变化,反推出应该执行什么动作(为了达到这个画面,手该怎么动)。
这与传统VLA有着本质区别:它不直接从“现在”跳到“动作”,而是要经过一下“未来”这个步骤。
如何实现?蚂蚁灵波团队主要将三个架构层面作为突破口。
![图片[4]-大事不好!机器人学会预测未来了-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/01/20260131013015818-1769794215-a38e2bc7e5d4e6af35f48aa6cad9aa4d.png)
首先就是视频与动作的自回归交错序列。
在LingBot-VA的模型里,视频Token和动作Token被放进了同一条时间序列里。
为了保证逻辑严密,团队引入了因果注意力(Causal Attention)。这就像给模型定了一条死规矩:只能用过去的信息,绝对不能偷看未来。
同时,借助KV-cache技术,模型拥有了超强的长期记忆。它清楚地知道自己三步之前做了什么,任务绝对不会失忆。
![图片[5]-大事不好!机器人学会预测未来了-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/01/20260131013019522-1769794219-c0f055984e8f25bcd97361ea1cb1d3b5.png)
其次是Mixture-of-Transformers (MoT) 的分工协作。
这一步主要是为了解决我们前面提到的表征缠绕的问题。
我们可以把过程理解为“左右互搏”,但又很默契的一种配合:
视频流:宽而深,负责繁重的视觉推演。 动作流:轻而快,负责精准的运动控制。
这两个流共享注意力机制,信息互通,但在各自的表征空间里保持独立。
这样一来,视觉的复杂性不会干扰动作的精准度,动作的简单性也不会拉低视觉的丰富度。
最后就是工程设计相关的工作。
毕竟光有理论是不好使的,“实践才是检验真理的唯一标准”:
部分去噪(Partial Denoising):做动作预测时,其实不需要每一次都把未来画面渲染得高清无码。模型学会了从带有噪点的中间状态里提取关键信息,计算效率大大提升。 异步推理(Asynchronous Inference):机器人在执行当前动作的时候,模型已经在后台疯狂计算下一步了。推理和执行并行,延迟感几乎消失。 FDM 接地(Grounding):为了防止模型想象力脱离现实,系统会用真实的观测数据不断校正想象,避免出现开放式的幻觉漂移。
实验结果与能力验证
在了解完理论之后,我们再来看实验效果。
蚂蚁灵波团队在真机实验和仿真基准上,对LingBot-VA进行了全方位的实测。
在真机测试中,LingBot-VA覆盖了三类最具挑战性的任务。
首先是长时序任务,比如准备早餐(烤面包、倒水、摆盘)、拆快递(拿刀、划箱、开盖)。
这些任务步骤繁多,但凡中间有一步有误,那可以说是满盘皆输。从LingBot-VA的表现来看,一个字,稳。
即便是不小心失败了,机器人也会记得进度,尝试重来。
第二类是高精度任务,比如擦试管、拧螺丝。
这要求动作精度达到毫米级,得益于MoT架构,动作流不再受视觉噪声的干扰,手极稳。
刚才我们已经看了擦拭管的案例,再来看个拧螺丝的:
第三类任务是针对可变形物体,例如折衣服、折裤子。
这些任务的难点在于物体处于一个随时变化的状态,但LingBot-VA通过视频推演,预判了布料的形变,操作行云流水。
除此之外,LingBot-VA在RoboTwin 2.0和LIBERO这两个硬核仿真基准上,也是很能打的。
尤其是在RoboTwin 2.0的双臂协作任务中,无论是简单的固定场景(Easy),还是复杂的随机场景(Hard),LingBot-VA都展现出了不错的实力:
RoboTwin 2.0 (Easy):成功率92.93%,比第二名高出4.2%。 RoboTwin 2.0 (Hard):成功率91.55%,比第二名高出4.6%。
![图片[6]-大事不好!机器人学会预测未来了-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/01/20260131013020938-1769794220-e3146dbf1c09338cda7a3eb0ba426505.png)
而且有一个趋势非常明显:
任务越难、序列越长(Horizon变大),LingBot-VA的领先优势就越大。
在 Horizon=3 的长任务中,它的优势甚至扩大到了9%以上。
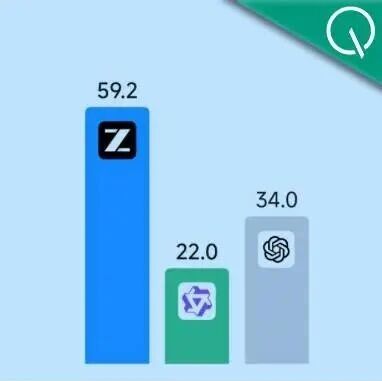
而在LIBERO基准测试中,LingBot-VA更是拿下了98.5%的平均成功率,刷新了SOTA记录。
![图片[7]-大事不好!机器人学会预测未来了-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/01/20260131013022254-1769794222-2f99b1bcab04fb511748243f622f8669.png)
总结一下,通过这些实验,我们可以清晰地看到LingBot-VA的三个核心特质:
长期记忆:在一个来回擦盘子的计数任务中,普通VLA模型擦着擦着就忘了擦了几下,开始乱擦;LingBot-VA 则精准计数,擦完即停。这就是KV-cache的起到的作用。 少样本适应:面对全新的任务,只需提供50条左右的演示数据,稍微微调一下,它就能学会。这比那些动辄需要成千上万条数据的模型,效率高了几个数量级。 泛化能力:训练时用的是某种杯子,测试时换个形状、换个颜色,或者把杯子随便摆个位置,它依然能准确识别并操作。
![图片[8]-大事不好!机器人学会预测未来了-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/01/20260131013030560-1769794230-b72ff178f7b94bdb836b08bede1da1aa.gif)
连续四天开源,已经产生影响
把时间轴拉长,回看这四天的连续开源,我们会发现蚂蚁灵波下了一盘大棋。
因为这四个开源项目拼凑在一起,就会形成一条非常清晰的技术主线:
Day 1: LingBot-Depth——解决“看清”的问题。让感知能够更加清晰。 Day 2: LingBot-VLA——解决“连接”的问题。打通语言、视觉到动作的通用接口。 Day 3: LingBot-World——解决“理解”的问题。构建可预测、可想象的世界模型。 Day 4: LingBot-VA——解决“行动”的问题。把世界模型真正嵌入控制闭环,让想象指导行动。
这四块拼图凑在一起,释放了一个强烈的信号:
通用机器人正在全面走向视频时代。
视频,不再仅仅是训练用的数据素材,它正在成为推理的媒介,成为连接感知、记忆、物理和行动的统一表征。
这对于整个行业来说,价值是巨大的。
对通用机器人来说,长任务、复杂场景、非结构化环境,这些曾经的硬伤,现在有了系统性的解法。
从具身智能路线来看,世界模型不再是一个可选项,它正式成为了机器人的中枢能力,从“能动”进化到“会想再动”。
并且蚂蚁灵波的持续不断地开源动作,不仅仅是提供了代码、模型这么简单,更是一条可复现、可扩展的技术范式。
而蝴蝶效应也在行业中开始显现。
就在这两天,谷歌宣布通过Project Genie项目让更多人体验Genie 3;宇树科技宣布开源UnifoLM-VLA-0……
海外媒体也对蚂蚁灵波的开源动作有了不小关注,点评道:
蚂蚁集团发布了名为LingBot-World的高质量机器人AI模拟环境。这家中国金融科技公司完善了一套完整的开源工具包,用于物理AI系统的开发。这也是在全球机器人领域主导权争夺战中的一项战略性举措。
![图片[9]-大事不好!机器人学会预测未来了-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/01/20260131013036113-1769794236-2a1579c24c130e16e0778836cbbb0fda.png)
嗯,蚂蚁灵波的压力是给到位了。
总而言之,LingBot-VA的出现,标志着世界模型第一次真正站上了机器人控制的主舞台。
项目地址:
https://technology.robbyant.com/lingbot-va
GitHub地址:
https://github.com/robbyant/lingbot-va
项目权重:
https://huggingface.co/robbyant/lingbot-va
https://www.modelscope.cn/collections/Robbyant/LingBot-va
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
🌟 点亮星标 🌟
<原文链接:https://mp.weixin.qq.com/s/xqE6C72usddKMc4EH89myA













暂无评论内容