


梦晨 发自 凹非寺
量子位 | 公众号 QbitAI
智谱AI上市后,再发新成果。
开源轻量级大语言模型GLM-4.7-Flash,直接替代前代GLM-4.5-Flash,API免费开放调用。
![图片[1]-智谱新模型也用DeepSeek的MLA,苹果M5就能跑-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/01/20260121024102766-1768934462-f279391a07278087b246368f308a7fdc.png)
这是一个30B总参数、仅3B激活参数的混合专家(MoE)架构模型,官方给它的定位是“本地编程与智能体助手”。
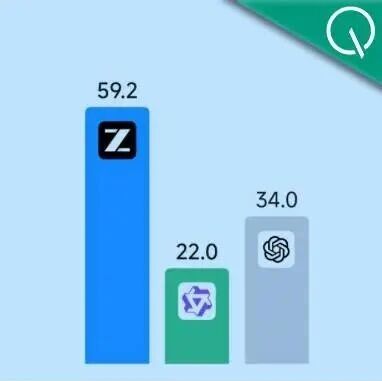
在SWE-bench Verified代码修复测试中,GLM-4.7-Flash拿下59.2分,“人类最后的考试”等评测中也显著超越同规模的Qwen3-30B和GPT-OSS-20B。
![图片[2]-智谱新模型也用DeepSeek的MLA,苹果M5就能跑-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/01/20260121024103555-1768934463-58daf6735ce27f007a6cd4dc4061817f.png)
作为去年12月发布的旗舰模型GLM-4.7的轻量化版本,GLM-4.7-Flash继承了GLM-4系列在编码和推理上的核心能力,同时针对效率做了专门优化。
除了编程,官方还推荐将这个模型用于创意写作、翻译、长上下文任务,甚至角色扮演场景。
30B参数只激活3B,MLA架构首次上线
GLM-4.7-Flash沿用了该系列的”混合思考模型”的设计。
总参数量300亿,但实际推理时仅激活约30亿参数,使模型在保持能力的同时大幅降低计算开销。
上下文窗口支持到200K,既可以云端API调用,也支持本地部署。
目前官方还没有给出技术报告,更多细节还要从配置文件自己挖掘。
![图片[3]-智谱新模型也用DeepSeek的MLA,苹果M5就能跑-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/01/20260121024105660-1768934465-e894a52ae86678b786fb2dde6997df60.png)
有开发者注意到一个重要细节:GLM团队这次首次采用了MLA(Multi-head Latent Attention)架构。这一架构此前由DeepSeek-v2率先使用并验证有效,如今智谱也跟进了。
从具体结构来看,GLM-4.7-Flash的深度与GLM-4.5 Air和Qwen3-30B-A3B接近,但专家数量有所不同——它采用64个专家而非128个,激活时只调用5个(算上共享专家)。
![图片[4]-智谱新模型也用DeepSeek的MLA,苹果M5就能跑-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/01/20260121024106528-1768934466-0b710a427287e90fdade355cb7f3ee3e.png)
目前发布不到12小时,HuggingFace、vLLM等主流平台就提供了day0支持。
![图片[5]-智谱新模型也用DeepSeek的MLA,苹果M5就能跑-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/01/20260121024107952-1768934467-2f2a5b860b2206adfea2a7c2b7e7d022.png)
![图片[6]-智谱新模型也用DeepSeek的MLA,苹果M5就能跑-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/01/20260121024108573-1768934468-06d669c0597299d3e42cd80e298e19d7.png)
官方也在第一时间提供了对华为昇腾NPU的支持。
![图片[7]-智谱新模型也用DeepSeek的MLA,苹果M5就能跑-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/01/20260121024110780-1768934470-8595e7d6c9d3815a8a59bdbfbab5eade.png)
本地部署方面,经开发者实测在32GB统一内存、M5芯片的苹果笔记本上能跑到43 token/s的速度。
![图片[8]-智谱新模型也用DeepSeek的MLA,苹果M5就能跑-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/01/20260121024111244-1768934471-5e0c7120dc3147bd554ace5b6d025577.png)
官方API平台上基础版GLM-4.7-Flash完全免费(限1个并发),高速版GLM-4.7-FlashX价格也相当白菜。
![图片[9]-智谱新模型也用DeepSeek的MLA,苹果M5就能跑-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/01/20260121024112137-1768934472-91fb7c0ca95d7ef7ca5ea71ad16bcfd4.png)
对比同类模型,在上下文长度支持和输出token价格上有优势,但目前延迟和吞吐量还有待优化。
![图片[10]-智谱新模型也用DeepSeek的MLA,苹果M5就能跑-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/01/20260121024114347-1768934474-d859d3da5f374837d97ffe3312e9ebb2.png)
HuggingFace:
https://huggingface.co/zai-org/GLM-4.7-Flash
参考链接:
[1]https://x.com/Zai_org/status/2013261304060866758
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
👑 年度「AI 100」产品榜单正式发布!
量子位智库通过三大板块——最强综合实力的「旗舰AI 100」、最具未来潜力的「创新AI 100」和十大热门赛道代表产品,全面梳理2025年度国内C端AI产品的发展脉络与创新成果。
![图片[11]-智谱新模型也用DeepSeek的MLA,苹果M5就能跑-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/01/20260121024116405-1768934476-6878a47d86e6660808cf5756c61e03b2.jpeg)
<原文链接:https://mp.weixin.qq.com/s/orYaU2dLBSyRwkd6KygGaQ














暂无评论内容