



闻乐 发自 凹非寺
量子位 | 公众号 QbitAI
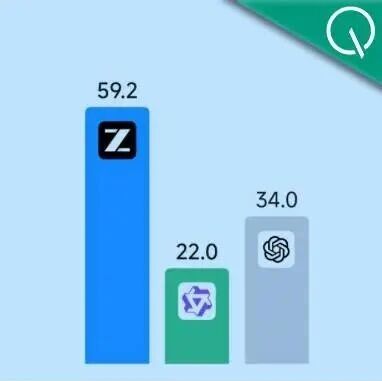
英伟达小模型持续获胜。
ARC-AGI 2最新成绩,4B小模型NVARC以27.64%的公开榜成绩力
且每任务成本仅20美分,大约是GPT-5 Pro单任务成本(超过7美元)的1/36。
![图片[1]-英伟达4B小模型击败GPT-5 Pro!成本仅1/36-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/12/20251209152041314-1765264841-57b938e234051397085a3ede78ec18ef.png)
据官方分析,此次NVARC夺冠的亮点在于零预训练深度学习方法
而ARC-AGI 2确实是一个消除了与公共训练数据重叠的更高难度测试,
![图片[2]-英伟达4B小模型击败GPT-5 Pro!成本仅1/36-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/12/20251209152042971-1765264842-7d4aaf17e0a355fb9ac6c34f46048795.png)
成绩出炉后,官方访谈到了NVARC团队的Jean-
![图片[3]-英伟达4B小模型击败GPT-5 Pro!成本仅1/36-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/12/20251209152043496-1765264843-11561aa9f84145a200bc111780a84e8f.png)
快来看看“性价比之王”是如何“练”成的?
不靠参数堆料
英伟达的策略是将复杂推理移至离线的合成数据管道,
简单来说就是大规模合成高质量数据,然后对现有模型进行优化,
![图片[4]-英伟达4B小模型击败GPT-5 Pro!成本仅1/36-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/12/20251209152044431-1765264844-16fd1fca66d15d9c6aea8d6486e5b2fe.png)
由于Kaggle比赛对计算资源限制非常严格,团队意识到,
因此他们改变了思路,决定将最烧钱的计算工作转移到离线完成。
团队从H-ARC、
![图片[5]-英伟达4B小模型击败GPT-5 Pro!成本仅1/36-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/12/20251209152044126-1765264844-62387abe0cf19cece93807d3dc860a8a.png)
为了确保数据质量,他们将复杂的推理管线拆分成不同的阶段,每个阶段都可以独立验证。
通过这种方式,他们建立了一个含320万+
![图片[6]-英伟达4B小模型击败GPT-5 Pro!成本仅1/36-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/12/20251209152045425-1765264845-ca07f99dc85732c0e6334e363847c4df.png)
这里忍不住提一嘴,哈萨比斯刚强调了Scaling Law的重要性,那么合成数据的Scaling怎么不算呢(doge)?
![图片[7]-英伟达4B小模型击败GPT-5 Pro!成本仅1/36-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/12/20251209152046262-1765264846-91dbb3e79ba8f09bfa16887d108f9353.png)
言归正传,
![图片[8]-英伟达4B小模型击败GPT-5 Pro!成本仅1/36-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/12/20251209152046928-1765264846-a31873ca1293f166ec423c80b03f6570.png)
训练时借助NeMo RL框架和Megatron后端进行监督微调。
不过,让模型取得优异成绩的关键一步在于测试时微调(TTFT)
针对ARC-AGI-2“每个任务都是全新规则”的特点,
而对ARChitects方法的改进在于解码阶段DFS算法做了
同时统一了8种数据增强操作评估候选解,
![图片[9]-英伟达4B小模型击败GPT-5 Pro!成本仅1/36-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/12/20251209152048890-1765264848-429ac300fef02251ef29e20a6b0d711c.png)
在竞赛后期,团队还应用了“少即是多”的TRM方法,
那么问题来了,有人会说这样训练出来的小模型不就是做题机器吗?
但更值得关注的或许不在于模型本身,而在于实现突破的方法。
在特定领域任务中,小模型经过针对性优化,性能并不逊色,
将正确的方法用在正确的地方,将会实现更大的价值。
![图片[10]-英伟达4B小模型击败GPT-5 Pro!成本仅1/36-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/12/20251209152048112-1765264848-b322e15025eaae28f63ae61ffb81232a.png)
借用这位网友所说,模型或许应该被设计得更加“敏捷”。
论文地址:https://drive.google.com/
参考链接:
[1]https://developer.nvidia.
[2]https://arcprize.org/blog/
[3]https://www.kaggle.com/
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —













暂无评论内容