



从没想到啊! 浓眉大眼的赛博菩萨 - CloudFlare 又宕机了!
就在 11 月 18 号,上次大宕机直接搞挂了 20% 的互联网流量,让客户痛失 4 个 9 的 SLA,也让很多用户质疑:你这家伙到底能不能行啊?
不了解上次宕机的朋友移步我的上一篇文章。
2019 年以来最大的宕机事件,号称赛博菩萨的 CloudFlare 是如何搞挂 20% 的互联网流量的?
周五的我,一边刷着 java 面试题准备找工作,一边时不时地瞄着 HackerNews,突然冒出来这么一条新帖子:CloudFlare 又挂了,帖子的链接指向 CloudFlare 的官网地址。

这时候我还半信半疑,结果一点开就发现一个水灵灵的默认服务器内部错误的 500 错误页面
事情开始变得好玩了,自家官网都直接 500 了。
不过这还不算完,随后全球各地的程序员纷纷来这个帖子里报告新情况:
Claude 也打不开了
Notion 也打不开了
NPM 也打不开了
Shopify 也打不开了
... ...
而且上面这些网站清一色的全部显示的是和 CloudFlare 官网一样的 500 错误页面。
很快,CloudFlare 的状态更新页面发布了此次问题的追踪情况:
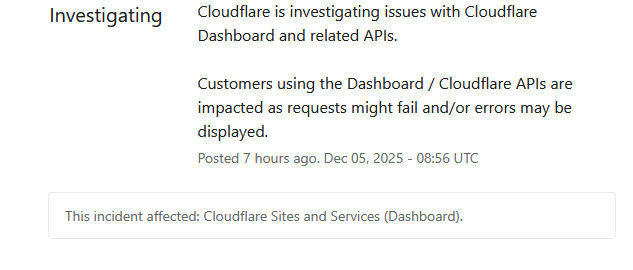
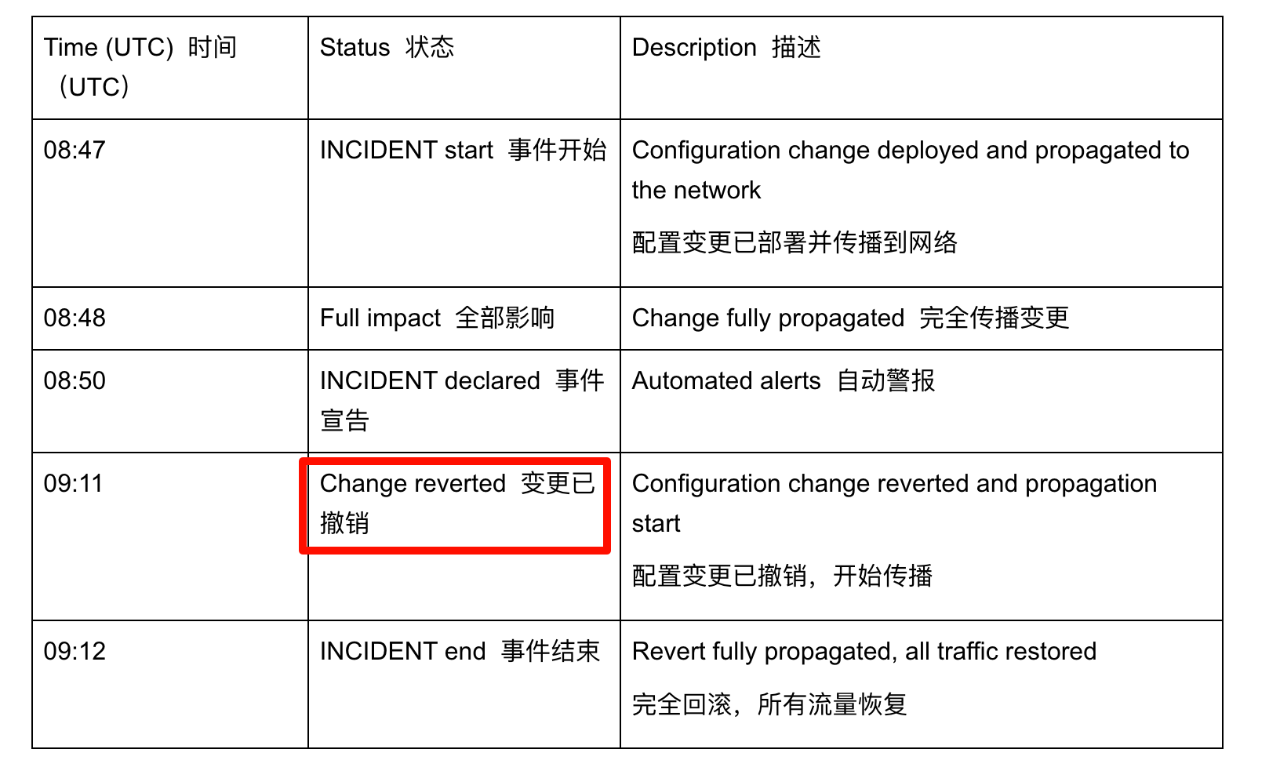
不过和上次不一样的是,这次事故的恢复速度还是很快的,大概的时间线如下:
8:56 发现问题 (实际发生问题要稍早于这个时间)
9:12 问题修复
9:20 问题确认已得到解决
总影响时间大约是 25 分钟。
(上面的是状态页面更新的时间,问题报告里提到事故是 8:47 发生的,9:12 修复之后就全好了)
而且此次受影响的流量也没有上次的大,这次只有大约 28 % 的 HTTP 流量出了问题。
但是!但是啊朋友们,距离上次大宕机仅仅 17 天,又来了这一出,实在有点说不过去,很多人都很好奇这次的事故原因。
终于,在北京时间的 6 号凌晨,让我等到了这个事故分析报告。
报告开头,当然是 sorry 啦,这么短的时间内中断互联网 2 次,确实得好好道歉(尤其是对信任他们的客户,其实我这类的免费使用者更多的是好奇和凑热闹...
回到这次事故的原因,简单来说就是:
为了修复近期被暴漏出来的 React 组件的安全问题,CloudFlare 把防火墙缓存 HTTP 请求的缓冲区大小从 128 Kb 改成了 1Mb,改完之后发现他们有一个内部工具一直在报错。
他们想:反正是个内部工具,索性先禁用掉吧!
于是通过配置更新系统禁用了这个内部工具,当这个系统几秒钟内把配置变更推送到所有节点之后,触发了旧版本流量代理程序中的一个 Lua 代码的空指针 bug,直接跳 500 错误页面了。
那么究竟是什么样的情况触发了这个 bug,发生 bug 的代码长什么样?
接着往下看。
聊细节之前,要先说一下 CloudFlare 防火墙的工作机制。
上一篇文章也提到了,CloudFlare 会帮你进行防御 DDoS 攻击,其中就是防火墙在干活。
防火墙会对每个 HTTP 请求进行分析,分析的方法就是对这个 HTTP 请求应用一系列的规则,这些规则通常有这么几类:
block,阻挡,也就是这个请求看起来不对,应该阻止其继续访问
log,写日志,也就是这个请求看起来可疑,需要记下来以供后续分析
skip,跳过,也就是不执行当前规则的校验
那么还有一个类型,叫做 execute (执行),这类规则会让程序去执行另外一套规则进行分析评估。
这次他们观测到的内部工具发生的错误,就是来自这种 execute 类型的规则。
当通过配置更新系统把这个出问题的规则禁用之后,程序对这个规则的分析评估被跳过了,这符合预期,没啥问题。
但是!
但是,跳过之后,当程序随后在汇总规则的执行结果时出了问题。
下面这段代码就是罪魁祸首,可以看到,当规则的类型时 execute 的时候,程序想当然的认为 rule_result.execute 对象是存在的,直接尝试访问这个对象的字段。

但是,由于这个规则被禁用了(跳过了),当程序走到这里的时候,rule_result.execute 这个对象是不存在的!
来来来,上课了!
当你尝试访问一个不存在对象的字段时,会发生什么呀?
对了!空指针异常。

这个 bug 之所以没有被发现,是因为 Cloudflare 此前从来没有禁用过 execute 类型的规则!!
他们之前也禁用过各种规则,但是从来没有禁用过 execute 类型的规则!
这就好比那个测试人员走进酒吧的笑话,说:
测试人员走进酒吧,点了 1 杯鸡尾酒,点了 null 杯鸡尾酒,点了 -1 杯鸡尾酒,一切正常。
真正的客人走进酒吧,问哪里有厕所,酒吧就崩溃了。
说这个的意思就是,你们这么大一公司,测试用例也不完善啊?
问题代码找到了,不过这次貌似并没有修复这个代码 bug,而是把做的配置更新(也就是不再禁用这个 execute 规则了)给回滚了,这确实是最快速恢复服务的方法。
(回头你们处理生产环境问题时,也应该是这个思路,先别急着修 bug,先把服务恢复了!
这次事件到这里算是告一段落,但是不到一个月内发生 2 次重大事故,给 Cloudflare 造成的影响还是很大的,上次事故之后他们承诺做一些应对措施,但没有给出具体的整改进度,这次 Cloudflare 直接宣布:
下周末之前,我们会更新这些整改措施的详细计划和进度,在此之前锁定所有生产系统的变更,确保不会再出现类似的问题。
言下之意:这系统现在跑的好好的,谁都先别动。

那么整改到底做的怎么样呢?我们拭目以待!
<













暂无评论内容