



鹭羽 发自 凹非寺
量子位 | 公众号 QbitAI
一个APP就能搞定爆款视频!这届AI玩家也太猛了。
能捏脸、能控色、会排版、全模态、戏感强还保真……
划重点,几乎只有你想不到的,就没有它做不到的。
不卖关子了——
这款全能创作搭子就是阿里最新上线千问APP的Wan2.7,好玩程度直接硬控我一整天。
不妨先来段视频感受一下,be like:
Prompt:生成一段视频,一个男人非常吃惊地看向镜头,镜头拉远,一群人都很吃惊,镜头翻转,原来是他们看到了Wan2.7的广告牌。
人物表情生动自然,镜头衔接流畅,都相当符合Prompt要求,尤其是群像塑造上,真正做到了“千人千面”。
同时还自动生成了匹配的人声音效,就这成片给到一个夯!
难度升级,再来一个图生视频试试,比如喂给AI一张图片:
![图片[1]-Sora向左,阿里向右:全能演技派模型登场千问APP-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/04/20260404011836134-1775236716-eb8ed468a411437e087105d21dc05051-scaled.jpeg)
以及一段音频:
Prompt:根据图片和音频生成一段萨克斯表演。
nice!光影变幻间,即刻上演一场精彩的单人萨克斯演出:
再加点料,在原视频基础上补充一张尾帧图,让演奏者丝滑切换:
Prompt:根据图片续写该视频,让女性演奏家加入表演。
![图片[2]-Sora向左,阿里向右:全能演技派模型登场千问APP-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/04/20260404011840322-1775236720-285ce2020aa1c52ce84d8200662b856e.jpeg)
效果是酱紫的:
而这些通通都是我在千问APP上完成的,操作非常简单,只需在“AI视频”中上传刚刚生成的第一段视频,以及尾帧图片即可。
![图片[3]-Sora向左,阿里向右:全能演技派模型登场千问APP-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/04/20260404011846552-1775236726-a85baffacf4423de13a3f76ba7115a65.gif)
这一次,不止视频生成得到史诗级增强,图片能力也直接next level。
无论是8色HEX精准控制还是3K tokens超长文本支持,AI创作这件事都在千问APP中变得so easy~
话不多说,直接深度开测。
这届AI来了位实力演技派
交互页面倒是没有比较大的改动,要么创作面板,要么chat对话。
总之,以前千问APP怎么用的,现在就还怎么用。
![图片[4]-Sora向左,阿里向右:全能演技派模型登场千问APP-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/04/20260404011849150-1775236729-6f6ed9528f87ffe98e365bbaaad243a1.jpeg)
主要是新增了视频编辑、视频续写、动作模仿能力,加上模型能力Pro,下面我们以具体的创作过程一一道来。
先看图像生成。
这次Wan2.7-Image的亮点是“千人千面”,比如在人物脸部上,用户可以自定义五官细节,包括骨相、眼神、皮肤纹理等。
这里我们尝试用Wan2.7-Image复刻《哈利波特》原著中的斯内普教授形象:
一个大约35岁的男人,面色蜡黄,油腻的及肩黑发,显眼的鹰钩鼻,冷漠空洞、像黑色隧道一样的双眼。身穿一件高领黑色长袍,背景为霍格沃茨昏暗潮湿的地窖。
![图片[5]-Sora向左,阿里向右:全能演技派模型登场千问APP-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/04/20260404011852644-1775236732-7a5f1ff678da26f80dd59471d02c5fc4.png)
u1s1,说这是真人定妆照也不为过。眼神复杂幽深,连毛孔皱纹都清晰可见。
同样的,我们把提示词交给Gemini和ChatGPT。
![图片[6]-Sora向左,阿里向右:全能演技派模型登场千问APP-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/04/20260404011858400-1775236738-835f9075a660ca7d6a5c0fcade8f499a-scaled.jpeg)
△左:Gemini;右:ChatGPT。
显而易见,Gemini直接照搬电影版选角,ChatGPT在鹰钩鼻的塑造上并不贴合。但都比电视剧版好太多……(doge)
Wan2.7-Image还具有调色盘能力,比如这个实用性的场景设计:
一张赛博朋克风格的深夜街道照片,细雨蒙蒙,画面主色调选择蓝色RGB(0,70,255)。镜头焦点是一个发光的霓虹灯招牌,上方写着大而清晰的汉字“未来之城”,下方写着手写体英文“Neo Metropolis”。
![图片[7]-Sora向左,阿里向右:全能演技派模型登场千问APP-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/04/20260404011903626-1775236743-f0f356cdc49ed165d391caa4fe7ec7e2.png)
将图片导入PS,可以直观看到,画面主色调精准落在蓝色系中,色差控制在合理的误差范围之内。
![图片[8]-Sora向左,阿里向右:全能演技派模型登场千问APP-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/04/20260404011910374-1775236750-bc73af250f101fa08ad3f28740816327.png)
另外,中英双语的文字渲染也没有出现乱码的情况。据官方介绍,Wan2.7-Image还能支持最高3K token的超长文字输入,可以写满足足一整页A4纸。
这次Wan2.7的视频生成能力,也有惊喜。
比如让千问APP帮忙手搓一个旅游Vlog,咱也来赶赶时髦。
根据六宫格参考图生成一个巴西旅游Vlog。
![图片[9]-Sora向左,阿里向右:全能演技派模型登场千问APP-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/04/20260404011913579-1775236753-6cd90bb87570282d589c05f5383a750d.jpeg)
好好好!也是在地球另一端感受到了桑巴热情。
要是对视频细节不满意,还可以进行局部编辑,比如原视频是这样的:
只需输入提示词+上传参考图,就能将胶片一键替换成盘子。
将视频中的胶片替换为图片中的盘子。
且看盘子上的反光,细节好评!
修改静态主体还不够,我还能直接用千问APP的视频模仿功能,无痛学习新动作~
比如我觉得这个小哥的动作很丰富:
尝试套到另一个角色身上:
让图片中的人物模仿视频中的人的手势动作,保持双手配合和手势变化过程清晰可见。
最后来玩个有意思的:拍好莱坞大片!
看不够,那就用视频续写延长战斗:
(无奖竞猜:男人为何如此惊恐?)
总之实测下来,Wan2.7给我最大的感受是——妙!
不仅仅可玩性大大提升,而且用起来还特别方便。
以前要创作一个视频,需要经过反复多次的修改剪辑,现在千问APP里就能一站式续写和参考重塑,迅速提炼出爆款视频的流量密码。
而且不只是日常的创意表达,专业的平面设计或者影视制作也能大用特用,就比如最近大热的AI演员、AI短剧,Wan2.7就能分得一杯羹。
而且演技还不输专业演员,够真实、够好用。
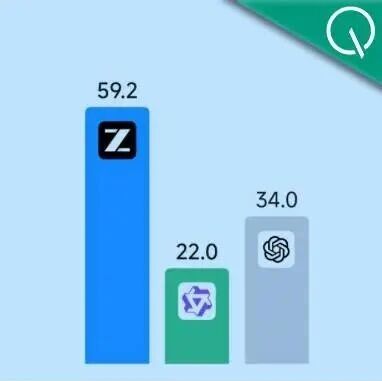
口说无凭,例如在人类偏好盲测评分中,Wan2.7-Image就位列国内生成模型第一,超过GPT Image 1.5,逼近Nano Banana Pro。
![图片[10]-Sora向左,阿里向右:全能演技派模型登场千问APP-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/04/20260404011916337-1775236756-38c0ed13112da5a9bdbab2badebb7ab3.jpeg)
实力能打+人人可用,那么这里就引出一个核心问题——
Wan2.7的发布,究竟代表着什么?
触手可及的创作,让人人都能生产爆款
显然,这并非一句“千问团队实现技术突破”就能简单带过的。
当我们将目光放大至整个行业,就会发现一个愈加明显的趋势清晰可见:
AI内容生成正在加速进入中国时间。
先看硅谷这边,曾经的AI生成龙头Sora悄然退场,以OpenAI为首的科技巨头纷纷从全面开花,转向Agent和底层推理的战略性单点收缩。
而例如视频生成这类高投入、慢回报的支线任务则被率先抛弃。
但与之形成对比的,是国内市场陆续迸发出多款高性能且全面的视频/图像生成模型。
归根结底,一方面是因为国内拥有更完善的C端场景(如短视频、电商),更适配AI内容生成的商业化落地。
另一方面,中国厂商也更注重培养模型的工程应用能力,尝试以更行之有效的迭代速度和更低的成本,加快AI融入创作者的工作流。
那么如何更高效地打通AI到创作者的“最后一公里”呢?
依据多年深厚的用户场景积累,阿里的答案简单粗暴——直给。也就是直接将最强模型同步装进APP。
![图片[11]-Sora向左,阿里向右:全能演技派模型登场千问APP-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/04/20260404011919987-1775236759-cae185da363139b5df660df44c590c8b.jpeg)
这源于阿里对市场的精准洞察:技术领先只是大模型的入场券,技术普惠才是产品真正的护城河。
细数阿里千问最近的动作,无一不在印证这点——春节期间“千问办事”的能力出圈,现在又将Wan2.7下放到移动端,就是为了让更多人能够第一时间享受到技术红利。
只要用户开始用了,就会发现AI创作这件事原来没有想象中那么难,即使是对模型一窍不通,也能通过最基础的功能按键和一句指令,稳定创造出高水准的视频。
可以预见的是,未来制作爆款视频和精美图像就会变得像点外卖、刷视频一样简单,到那一刻,才是真正打开了人人AI创作的大门。
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
🌟 点亮星标 🌟
<原文链接:https://mp.weixin.qq.com/s/hc0gyu23DeSn1EknMfhyHA













暂无评论内容