


闻乐 发自 凹非寺
量子位 | 公众号 QbitAI
Claude Code源码泄漏的余波,还在AI圈持续发酵!
说起来还挺反常,Claude几乎Contribute了所有RAG记忆项目,结果泄露的代码却显示——
它自己压根没在用主流的RAG技术??
![图片[1]-19岁,常青藤辍学,这群中国年轻人重构了AI记忆-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/04/20260404010952204-1775236192-f7b770d672effc40c4e373cbf609563f.png)
这就很矛盾了,Anthropic在官方文档和技术博客里,一直明确提到支持RAG检索。
![图片[2]-19岁,常青藤辍学,这群中国年轻人重构了AI记忆-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/04/20260404010955634-1775236195-e3963028875f60eb13ac7a35f6ad3891.png)
而它“弃用”传统RAG的玩法,其实恰恰也说明了一个问题:现有的RAG解决方案,性能并没有达标。
从2023年起,混合检索就成了记忆引擎的标配逻辑,向量+关键词、加权排序……这些套路不断迭代。
但随着AI记忆场景越来越复杂,传统RAG的瓶颈也彻底暴露,明明叫记忆引擎,却还在干着搜索引擎的活儿,只会匹配相似文本,做不到真正的理解,更谈不上联想推理。
那怎么办?答案很简单——
推倒,重来。
回头看AI记忆的演化路径,脉络其实非常清晰:
第一代是直接硬塞全量上下文,就像通读日记;第二代依靠向量+关键词匹配,类似查字典,可是只能找到相似内容,抓不住真实关联;
现在,第三代记忆模式已经来了。
能够自主联想、推理、跨结构建立关联的认知模型。
![图片[3]-19岁,常青藤辍学,这群中国年轻人重构了AI记忆-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/04/20260404010958721-1775236198-9ee077eccd245bcb0d62b1afb3e99471.gif)
中国团队自研架构领跑Benchmark
让AI能够实现推理与联想,大家都知道跨粒度记忆的有效组织是关键。
简单点说就是让AI能同时处理细颗粒的事实和粗颗粒的上下文,还能在它们之间自由跳转(切换关联)。
但这个问题正是2023到2026年间,整个记忆引擎行业难以突破的核心瓶颈。
不过最近,我们观察到一个平均年龄19岁的中国年轻团队,心流元素,给出了可行解法——
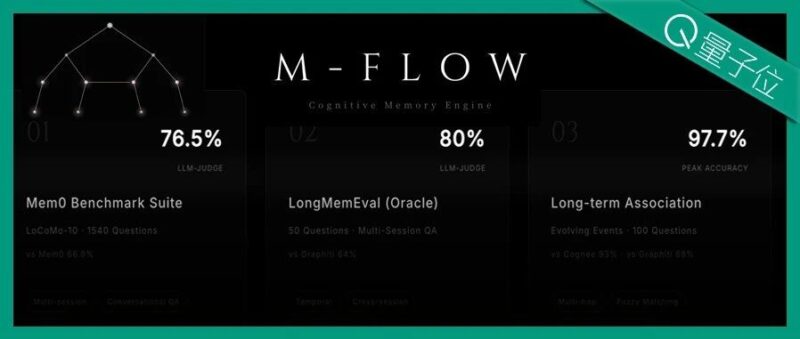
M-FLOW,凭借自研的图路由Bundle Search架构,实现了benchmark的现象级领先。
对比Mem0、Graphiti、Cognee等主流方法,M-FLOW在多轮对话、长期记忆、多跳推理三大核心场景下,性能优势显著。
对齐Mem0的官网benchmark测试(LoCoMo),领先Mem0 36%; 对齐Graphiti的官网benchmark测试(LongMemEval),领先Graphiti 16%; 在长期事件演变测试(EvolvingEvents)中,领先Cognee 7%,领先Graphiti 20%。
![图片[4]-19岁,常青藤辍学,这群中国年轻人重构了AI记忆-AI Express News](https://www.aiexpress.news/wp-content/themes/zibll/img/thumbnail-lg.svg) △测试未做任何筛选,采用行业通用Benchmark
△测试未做任何筛选,采用行业通用Benchmark
![图片[4]-19岁,常青藤辍学,这群中国年轻人重构了AI记忆-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/04/20260404011009288-1775236209-863f43bcb5e1d8f0c957bb47dafeec21.png) △测试未做任何筛选,采用行业通用Benchmark
△测试未做任何筛选,采用行业通用Benchmark深度测评之后,可以更清晰地看到在覆盖写入、检索、预处理、知识组织等环节等29项能力维度中,M-FLOW在绝大多数关键维度上都实现了完整支持。(下图可上下滑动完整查看)
![图片[5]-19岁,常青藤辍学,这群中国年轻人重构了AI记忆-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/04/20260404011013444-1775236213-46c72d50fb1967d0bd739afb259628f1-scaled.jpeg)
尤其在图增强检索、指代消解、多粒度索引等决定记忆质量的核心能力上表现突出。
这份成绩的背后,其实可以看到的是M-FLOW架构带来的系统性优势:
检索环节不依赖LLM,能够实现毫秒级响应; 在超大记忆量场景下,依然能保持接近常规Benchmark的稳定表现; 业内首个支持指代消解的记忆引擎,让AI对信息的理解更贴合人类思维(指代消解是指能区分事件中的“他”和“它”)。
![图片[6]-19岁,常青藤辍学,这群中国年轻人重构了AI记忆-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/04/20260404011015113-1775236215-f4afded41f3cd9a05ade192bddad2e95.gif)
而且基本没什么使用门槛,部署流程非常简单,在具备Docker环境时只需要一行代码就能完成接入。
![图片[7]-19岁,常青藤辍学,这群中国年轻人重构了AI记忆-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/04/20260404011018139-1775236218-21f453587c4a79d5920213c0eb5813ca.png)
当然了,虽然上手简单,但在部署之前,咱也先来说说大家好奇的问题:
M-FLOW是怎么做到的?
答案其实还是开头的那句话:推倒,重来。
与当前行业里大量同质化的记忆方案不同,M-FLOW并不是用LLM辅助检索来抬高Benchmark分数,也不是简单叠加功能。
准确说,它是从根本上重构了AI记忆的组织与使用体系。
让记忆会关联、能推理
事实上,所有RAG系统都会面临的一个问题是,给定用户查询,如何精准定位存储的相关知识?
主流方案的逻辑很直接,就是将文档切块、向量化后存入向量库,检索时按余弦相似度排序。
这种方式本质上只回答“哪段文本和查询语义最接近”这一个层级的问题,对简单事实查找的效果还不错,但在复杂场景中会完全失效,因为:
答案跨文档分布:文档切块间缺乏结构性连接,无法将分散在不同文档中的关联信息整合; 查询与存储粒度不匹配:宏观问题检索到琐碎片段,微观问题匹配到笼统摘要; 同实体异语境割裂:两份文档讨论同一实体但语境不同时,向量空间中距离遥远,无法建立关联。
究其原因,是因为平坦向量检索丢弃了知识的内在结构。
它能判断文本与查询的相似度,却完全不清楚这段文本在整个知识体系中的拓扑位置。
在这一点上,M-FLOW以图路由检索替代传统平坦检索,核心逻辑围绕分层知识拓扑展开,其核心洞察是:
不止找到“匹配的文本”,更要定位匹配点所属的完整知识结构,再对整个结构进行评分。
倒锥结构设计
M-FLOW将所有摄入的知识组织为一个四层有向图,形成一个倒锥(inverted cone):
![图片[8]-19岁,常青藤辍学,这群中国年轻人重构了AI记忆-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/04/20260404011021933-1775236221-531c840020f9f2a21e6163a0b7660e10.png)
这个结构的方向性是反直觉的:在传统的知识图谱或分类树中,越往下越具体。
但在M-FLOW中,搜索的“入口在锥尖”(细粒度的Entity和FacetPoint是最容易被向量搜索精确命中的),而搜索的“目标在锥底”(Episode是最终返回给用户的知识单元)。
信息流从尖锐的匹配点向下汇聚到宽广的语义落点。
这打破了“从上到下浏览”的传统检索范式。
用户不是在层级中逐层缩小范围,而是系统在最尖锐的点上捕获信号,然后沿图结构向下传播到它所归属的完整语义单元。
![图片[9]-19岁,常青藤辍学,这群中国年轻人重构了AI记忆-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/04/20260404011024833-1775236224-b850cf96d3fff44500eaa1c9c06aac47.gif)
这是一个从细到粗的过程,先在最尖锐的点上捕获信号精准瞄准,然后沿图结构向下传播到它所归属的完整语义单元。
图路由Bundle Search的工作方式
当查询到达时,系统不是简单地找到最近的节点。
它通过评估图中所有可能到达每个Episode的路径,找到最优的Episode。
阶段一:在锥尖广撒网
查询被向量化后,同时在七个向量集合中搜索,从锥尖到锥底覆盖每一层。每个集合返回最多100个候选。
最容易被精确命中的是锥尖处的节点,一个Entity名称、一个FacetPoint的断言。
这些细粒度锚点的语义极度聚焦,向量距离小。
锥底的Episode摘要也可能被命中,但因为语义更宽泛,匹配通常不如锥尖精确。
阶段二:投影到图中
这些锚点被用作进入知识图谱的入口节点。
系统提取它们周围的子图,边、邻居、连接关系,然后扩展一跳邻居。
这将一组孤立的向量命中点转化为一个连通的拓扑结构。
阶段三:从锥尖向锥底传播代价
这是核心步骤,也是图路由Bundle Search的本质——
在锥尖捕获信号,沿图边向锥底传播,在Episode处汇聚评分。
对于子图中的每个Episode,系统评估从锚点到达它的所有可能路径:
![图片[10]-19岁,常青藤辍学,这群中国年轻人重构了AI记忆-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/04/20260404011037914-1775236237-3552d52e13f2a510d21718015eba7259.png)
每条路径的代价由三部分构成:
起始代价,锚点的向量距离(信号的尖锐程度); 边代价,沿途每条边的向量距离(连接关系与查询的相关度)加跳跃惩罚; 未命中惩罚,边没有被向量搜索命中时的默认高代价。
Episode的最终得分是所有路径中的最小代价。
三大打破常规的设计
1.边也携带语义,成为主动过滤器
传统知识图谱中,边(图谱中节点之间的连线)只是作为类型标签,比如’works_at’、’located_in’,不参与语义检索。
查询一个图时,你要么遍历边,要么忽略边,因为边本身不携带可被搜索的语义。
而M-FLOW中,每条边都附带自然语言描述文本,这些文本会被向量化、同样参与搜索。
这意味着边不再是被动连接器,而是主动的语义过滤器。
![图片[11]-19岁,常青藤辍学,这群中国年轻人重构了AI记忆-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/04/20260404011039833-1775236239-5295d10ae009c699dcc2ef0242a1567a.gif)
在代价传播阶段,系统不仅知道两个节点之间存在连接,还知道这条连接关系本身与当前查询有多相关。
这样一来,即便一条边的两个节点都被搜索命中,只要这条边本身的语义和查询无关,就会被判定为高代价,从而直接切断这条不合理的关联路径。
2.取路径最小代价,而非平均代价
为什么取最小值呢?团队主要考虑到一个检索哲学——一条强的证据链就足以证明相关性。
一个Episode可能关联10个Facet,但9个与查询都无关。
传统方式会平均所有路径代价,这就会让无关路径拉高分数;
而M-FLOW只看那条最好的路径。
只要有一个Facet通过低代价路径连接到查询,这个Episode就应该被检索到。
这也对应了人类记忆的工作方式,比如你想起一件事,通常是因为某一个线索足够强烈,而不是因为所有线索都指向它。
3.惩罚直接命中,偏好精准锚点路径
这是最反直觉的设计,当查询直接匹配了Episode摘要时,系统反而对这条路径施加额外惩罚。
惩罚最直接命中的原因是,它们和很多查询看起来相关。
一个关于项目管理的Episode摘要,可能和任何提到项目或管理的查询都有不错的向量距离。
但这种匹配是宽泛的、缺乏焦点的,这其实也反映了众多RAG系统检索噪声的根本原因。
M-FLOW系统的设计偏好,是优先选择从锥尖(FacetPoint、Entity)出发的精确路径。
即使多走几跳,也优先选择它,直接的Episode命中只在没有更好替代路径时才胜出。
这样就确保了检索结果的精确性——不是什么都沾点边的宽泛摘要,而是有具体证据链支撑的Episode。
拓扑论证
要说这套机制为什么有效,根本优势还是在于图拓扑编码了向量本身无法捕获的知识组织结构。
多粒度均可找到锚点。比如问“数据库迁移发生了什么?” 这类宏观问题时,系统会直接匹配到Episode摘要。
虽然会受到直接命中惩罚,但因为没有更精确的锥尖路径,这条结果依然会胜出。
而像“P99目标是否低于500ms?” 这类精确问题,则会强匹配一个FacetPoint,从锥尖经过两跳到达Episode,极小的起始距离让整体代价非常低。
系统不需要人为选择粒度,倒锥拓扑会自动在最合适的层级找到锚点。
跨文档实体桥接。当“张博士在MIT工作”出现在文档A,“MIT发表了量子计算突破”出现在文档B时,两个Episode会共享同一个Entity节点:MIT。
用户查询MIT时,锥尖命中该实体,代价会同时向下传播到两个Episode,从而从两个独立文档中拿到关联结果,不需要LLM做额外推理,图结构本身就完成了桥接。
![图片[12]-19岁,常青藤辍学,这群中国年轻人重构了AI记忆-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/04/20260404011051617-1775236251-38eb092f3baec3f9a196dcd9c6b743ec.gif)
结构噪声过滤。在传统平坦检索中,很多语义相似但主题无关的文本片段会排在前面。
而在Bundle Search中,任何片段都必须沿着边追溯到某个Episode。
如果沿途的边和查询语义无关,路径代价会迅速升高,让不相关结果自然下沉。
图结构本身,就是一层强大的语义噪声过滤器。
代价传播即推理。图中的每一条路径,本质上都是一条推理链——
查询匹配这个事实→事实属于这个维度→维度属于这个事件。
路径代价量化了这条推理链的紧密程度,系统在2–3跳内就能完成轻量级多跳推理,检索阶段不需要调用LLM。
自适应置信度
并不是每一层向量集合对每个查询都同样可靠。
系统会为每个集合计算两个指标,绝对匹配强度与区分度,然后把集合分为“节点类”和“边类”,按置信度动态分配权重。
比如某一次查询中,Entity集合的置信度明显高于Facet集合,系统就会自动提高Entity路径的影响力。
它不是用固定权重,而是根据本次搜索中哪个粒度的命中更可信,实时调整检索策略。
一个额外的调节机制
还有一个额外的调节机制是,当某个Facet与查询向量距离极小、高度吻合时,系统会显著降低这条路径上的边代价和跳跃代价。
逻辑很直观,如果一个Facet已经几乎完美匹配查询,那么它到Episode的连接基本就是可靠的,不需要再通过边语义反复验证。
除此之外,系统还包含查询预处理、并行多模式调度、结果裁剪等机制……
所以总结来看,M-FLOW的检索并不是向量搜索+图数据库的简单叠加,图本身就是检索机制。
中国记忆引擎后发先至?
这个最普遍的问题,恰恰是AI记忆解决方案的核心症结。
从初代全量上下文硬塞式记忆,到第二代向量+关键词的检索式记忆,AI始终停留在文本形态匹配,离真正的理解与联想相去甚远。
而M-FLOW用图结构重构了AI记忆的底层逻辑,解决了记忆图谱的粒度与联系问题,让AI记忆完成了从形态相似匹配到联想与推理的跨越。
而且值得一提的是,这个项目是由一支平均年龄19岁、从常青藤辍学的团队独立开发的。
在AI圈里,天才少年的故事总是备受瞩目。在这次技术突破之后,我们也想知道:
这群年轻人,未来又可以走多远呢……
项目地址:https://github.com/FlowElement-ai/m_flow
产品网站地址:https://m-flow.ai
公司地址:https://flowelement.ai
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
🌟 点亮星标 🌟
<原文链接:https://mp.weixin.qq.com/s/6vRe448c-xxwPQoID0oUGA













暂无评论内容