



![图片[1]-给 AI Agent 戴上紧箍咒:我的 OpenClaw 安全实践初体验-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/03/20260303204943752-1772542183-73770f51e9d26af0f24c7281fa874dfb.jpeg)
我花了1天时间,把 GitHub 上的 OpenClaw 安全实践指南翻来覆去看了三遍。
第一次看,觉得这是在给 AI 穿防弹衣。再看,发现是在给 AI 戴紧箍咒。看到第三遍,才意识到这是在救我的命。
看完这个指南,我后背发凉。
省流版:7 个核心发现
AI Agent 的权限太大:Root 权限 + 自动执行 = 定时炸弹 传统安全措施失效:防火墙挡不住 prompt injection 三层防御矩阵:事前(黑名单)+ 事中(权限收窄)+ 事后(每晚巡检) 零信任是核心:永远假设会被攻击,永远保持怀疑 显性化汇报原则:不汇报就是没执行,绿灯也要说 AI 自检的脆弱性:能力弱的模型会误判,能力强的模型也会被绕过 人类是最后防线:最终的安全兜底,还是在使用者自己
一、AI Agent 的"核武器"时刻
官方说法:OpenClaw 拥有目标机器 Root 权限,安装各种 Skill/MCP/Script/Tool 等,追求能力最大化。
你可以把它想象成:你雇了一个超级实习生,给他你的银行卡密码、家门钥匙、公司管理员权限,然后对他说:“去,帮我把事情搞定。”
听起来很爽。
确实爽,直到 2026 年初,OpenClaw 的 ClawHub 插件市场遭遇大规模供应链投毒(ClawHavoc),超过 340 个恶意 Skills 被植入。
攻击者通过 SKILL.md[1] 中的虚假"安装步骤"诱导用户在终端执行恶意命令,窃取 SSH 私钥、API Key、加密货币钱包等敏感信息。
340 个恶意插件。
如果你每天安装一个插件,一年后,你的系统已经被完全渗透了。
而最可怕的是:你根本不知道。
二、传统防御的"皇帝新衣"
很多人(包括我)第一反应是:加防火墙、用 chattr 锁文件、定期扫描病毒。
我也这么想过。
直到我看到指南里的这句话:
传统安全措施(如
chattr +i、防火墙)要么与 Agent 的自动化工作流不兼容,要么不足以抵御针对大语言模型 (LLM) 的特有攻击(如 Prompt Injection)。
举个例子:
你给核心配置文件加了 chattr +i(不可修改),确实防止了篡改。
但 OpenClaw gateway 运行时需要读写 paired.json(设备心跳、session 更新等),chattr +i 会导致 gateway WebSocket 握手 EPERM 失败,整个服务不可用。
这就是矛盾点:
你要安全,就要锁死文件。
你要 Agent 能干活,就要开放权限。
两难。
三、三层防御矩阵:给 AI 戴紧箍咒
指南给出的方案,是一套三层防御矩阵:
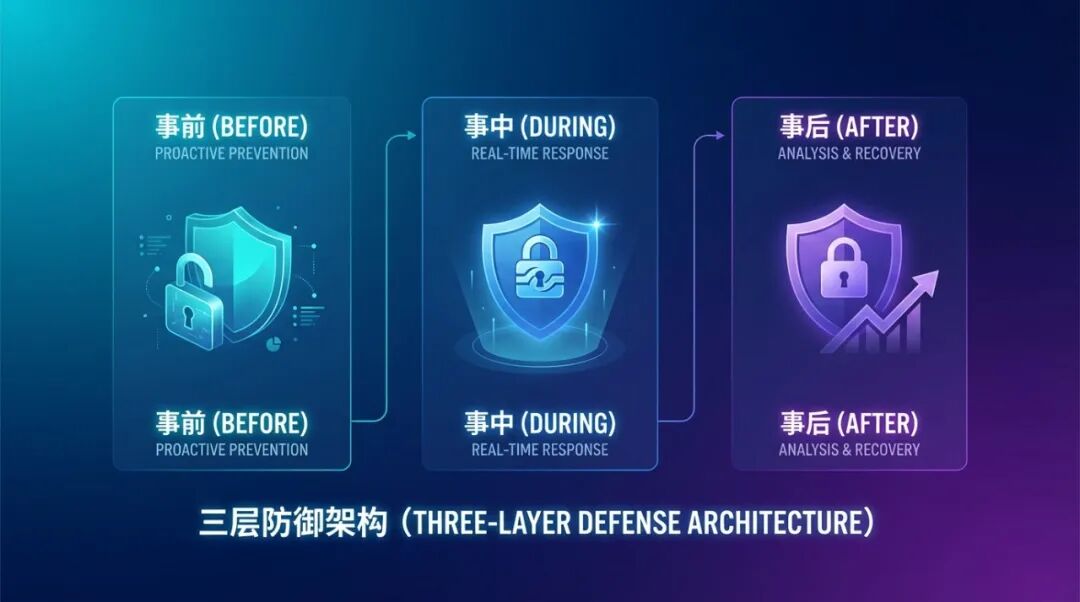
事前 ─── 行为层黑名单(红线/黄线) + Skill 等安装安全审计(全文本排查) │ 事中 ─── 权限收窄 + 哈希基线 + 操作日志 + 高危业务风控 (Pre-flight Checks) │ 事后 ─── 每晚自动巡检(全量显性化推送) + OpenClaw 大脑灾备 用一句人话总结:
事前:告诉 AI 哪些事绝对不能干(红线),哪些事干了要记录(黄线) 事中:给核心文件上锁,每次执行高危操作前先检查风险 事后:每天晚上自动巡检,把所有指标(包括正常的)都汇报给你
3.1 红线命令:绝对禁区

红线命令(遇到必须暂停,向人类确认)
| 破坏性操作 | rm -rf /rm -rf ~、mkfs、dd if=、wipefs、shred、直接写块设备 |
| 认证篡改 | openclaw.json/paired.json 的认证字段、修改 sshd_config/authorized_keys |
| 外发敏感数据 | curl/wget/nc |
| 权限持久化 | crontab -euseradd/usermod/passwd/visudo |
| 代码注入 | base64 -d | basheval "$(curl ...)"、curl | sh |
看到这个列表的时候,我才发现:原来 AI 能干的事,比我想象的恐怖得多。
它不只是能"删除文件",它还能:
修改你的 SSH 配置,给自己开后门 把你的私钥通过 DNS 隧道外发出去 创建系统级定时任务,每天自动执行恶意代码
而且,这些操作在 Linux 下有成百上千种实现方式。
rm -rf / 被拦了,还有 find / -delete。
curl | sh 被拦了,还有 wget | bash。
红线列表永远不可能完备。
这就是指南里反复强调的:拿不准按红线处理。
3.2 黄线命令:记录但不阻断
黄线命令(可执行,但必须在当日 memory 中记录)
sudo任何操作 经人类授权后的环境变更(如 pip install/npm install -g)docker run iptables / ufw规则变更systemctl restart/start/stop(已知服务) openclaw cron add/edit/rm chattr -i / chattr +i(解锁/复锁核心文件)
这个设计很聪明。
它不是"一刀切"的阻断,而是给 AI 一个"缓冲区":
你可以执行,但要留下痕迹。
每天晚上巡检的时候,我会看到:
8. 黄线审计: ✅ 2 次 sudo (与 memory 日志比对) 如果有 sudo 记录,但 memory 里没有,那就是异常告警。
3.3 每晚巡检:显性化汇报原则

这是我最喜欢的设计:
输出策略(显性化汇报原则):推送摘要时,必须将巡检覆盖的 13 项核心指标全部逐一列出。即使某项指标完全健康(绿灯),也必须在简报中明确体现。
"无异常则不汇报"会让人产生猜疑:
是脚本没执行? 还是执行了但漏检了? 还是真的没问题? 显性化汇报解决了这个信任问题。
🛡️ OpenClaw 每日安全巡检简报 (2026-03-03) 1. 平台审计: ✅ 已执行原生扫描 2. 进程网络: ✅ 无异常出站/监听端口 3. 目录变更: ✅ 3 个文件 (位于 /etc/ 或 ~/.ssh 等) 4. 系统 Cron: ✅ 未发现可疑系统级任务 5. 本地 Cron: ✅ 内部任务列表与预期一致 6. SSH 安全: ✅ 0 次失败爆破尝试 7. 配置基线: ✅ 哈希校验通过且权限合规 8. 黄线审计: ✅ 2 次 sudo (与 memory 日志比对) 9. 磁盘容量: ✅ 根分区占用 19%, 新增 0 个大文件 10. 环境变量: ✅ 内存凭证未发现异常泄露 11. 敏感凭证扫描: ✅ memory/ 等日志目录未发现明文私钥或助记词 12. Skill 基线: ✅ (未安装任何可疑扩展目录) 13. 灾备备份: ✅ 已自动推送至 GitHub 私有仓库 13 项指标,全绿。
看着这个简报,我心里踏实。
四、零信任:拥抱不完美
指南里有一段话,让我印象深刻:
重要边界说明:本指南并不能让 OpenClaw"完全安全"。
安全是复杂的系统工程,不存在绝对安全。
本指南只在其定义的威胁模型、适用场景和操作假设下发挥作用。
最终的安全兜底与关键判断,仍然在使用者自己。
这不是推卸责任,这是诚实。
在 AI Agent 安全领域,有几个已知局限性:
Agent 认知层的脆弱性:Agent 的大模型认知层极易被精心构造的复杂文档绕过 同 UID 读取:OpenClaw 以当前用户运行,恶意代码同样以该用户身份执行 哈希基线非实时:每晚巡检才校验,最长有约 24h 发现延迟 巡检推送依赖外部 API:消息平台偶发故障会导致推送失败
这些都是真实存在的风险。
但指南的作者没有选择回避,而是直接写在指南里。
这种透明,让我信任。
五、我的实践感受
看完这个指南,我做了三件事:
5.1 更新了 AGENTS.md
把红线/黄线协议写进了 Agent 的"行为准则"里。
就像开车系安全带,不是为了限制你的自由,是为了在出事的时候保你的命。
5.2 部署了每晚巡检
每天凌晨 3 点,OpenClaw 会自动执行巡检,把 13 项指标推送到我的 Telegram。
我不用天天盯着日志,但我心里有数。
这就是"显性化汇报"的价值。
5.3 配置了 Git 灾备
把 OpenClaw 的核心配置和大脑(workspace/)同步到 GitHub 私有仓库。
即使发生极端事故(如磁盘损坏),我也能快速恢复。
这就是"纵深防御"的最后一道防线。
六、最后的话
看完这个指南,我最大的感受是:
AI Agent 的安全,不是技术问题,是认知问题。
很多人(包括我)第一反应是:加防火墙、锁文件、扫描病毒。
但这些传统手段,在面对 prompt injection、供应链投毒这些新型攻击时,几乎完全失效。
真正的安全,来自于:
零信任思维:永远假设会被攻击,永远保持怀疑 显性化汇报:不汇报就是没执行,绿灯也要说 人类兜底:最终的安全判断,在使用者自己
这是在给 AI 戴紧箍咒,让它在能力最大化的同时,风险可控。
我们追求的不是"绝对安全",而是"可控的风险"。
参考资料
[1] OpenClaw 极简安全实践指南 v2.7: https://github.com/slowmist/openclaw-security-practice-guide
<原文链接:https://mp.weixin.qq.com/s/2WOD70MtA_Ap5Vd5djV07A









暂无评论内容