


梦晨 发自 凹非寺
量子位 | 公众号 QbitAI
2026年新年第一天,DeepSeek上传新论文。
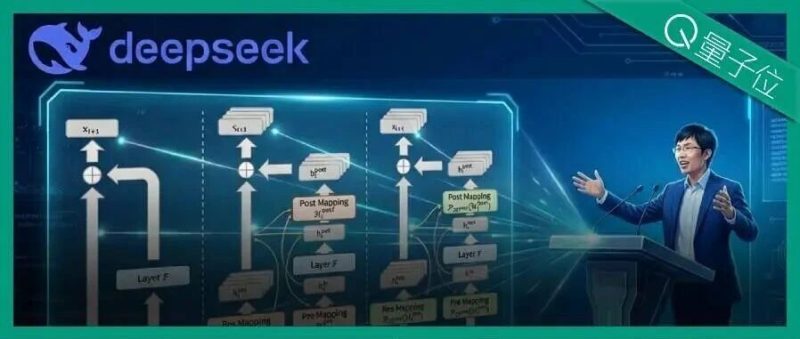
给何恺明2016成名作ResNet中提出的深度学习基础组件“残差连接”来了一场新时代的升级。
![图片[1]-DeepSeek改造何恺明残差连接!梁文峰亲自署名,十年首次重大升级-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/01/20260101204745982-1767271665-97e0c726d50725e2057d377e9b400916.png)
DeepSeek梁文峰亲自署名论文,共同一作为Zhenda Xie , Yixuan Wei, Huanqi Cao。
![图片[2]-DeepSeek改造何恺明残差连接!梁文峰亲自署名,十年首次重大升级-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/01/20260101204746644-1767271666-aa18b1d9e1e0236c4e6655eddf4bf1b0.png)
残差连接十年未变,扩展之后却带来隐患
残差连接自2016年ResNet问世以来,一直是深度学习架构的基石。
其核心机制简洁明了,x𝑙+1 = x𝑙 + F (x𝑙 ,W𝑙),即下一层的输出等于当前层输入加上残差函数的输出。
这个设计之所以成功,关键在于“恒等映射”属性,信号可以从浅层直接传递到深层,不经任何修改。
![图片[3]-DeepSeek改造何恺明残差连接!梁文峰亲自署名,十年首次重大升级-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/01/20260101204746880-1767271666-5eea1361df63c41a7bc887d63b10b124.png)
随着Transformer架构的崛起,这一范式已成为GPT、LLaMA等大语言模型的标准配置。
这个设计之所以成功,关键在于“恒等映射”属性,信号可以从浅层直接传递到深层,不经任何修改。
近期出现的Hyper-Connections(HC)试图打破这一格局。HC将残差流的宽度从C维扩展到n×C维,并引入三个可学习的映射矩阵来管理信息流动。
DeepSeek团队的实验表明,在这三个映射中,负责残差流内部信息交换的Hres矩阵贡献了最显著的性能提升。
![图片[4]-DeepSeek改造何恺明残差连接!梁文峰亲自署名,十年首次重大升级-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/01/20260101204747377-1767271667-ee54ea7728175b3917d6be0078e21d22.png)
但问题随之而来,当HC扩展到多层时,复合映射不再保持恒等性质。
论文中展示的27B模型训练曲线显示,HC在约12000步时出现了突发的损失激增,梯度范数也表现出剧烈波动。
![图片[5]-DeepSeek改造何恺明残差连接!梁文峰亲自署名,十年首次重大升级-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/01/20260101204748903-1767271668-65ff216538a36bb65ed2a34f981fc889.png)
研究团队计算了复合映射对信号的放大倍数:在HC中,这个值的峰值达到了3000,意味着信号在层间传播时可能被放大数千倍,或者相应地被衰减至近乎消失。
![图片[6]-DeepSeek改造何恺明残差连接!梁文峰亲自署名,十年首次重大升级-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/01/20260101204750636-1767271670-25b3434ed27b536f4f2b0c7134405054.png)
双随机矩阵的三重保障
DeepSeek论文的核心思路是将残差映射矩阵约束到一个特定的流形上,一个由双随机矩阵构成的Birkhoff多面体。
![图片[7]-DeepSeek改造何恺明残差连接!梁文峰亲自署名,十年首次重大升级-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/01/20260101204750425-1767271670-f7708dfba5f30908a14b50e918385011.png)
双随机矩阵的每一行和每一列之和都等于1,所有元素非负。这种约束带来了三个关键的理论性质。
第一是范数保持:双随机矩阵的谱范数不超过1,这意味着信号在经过映射后不会被放大,有效防止了梯度爆炸。
第二是组合封闭:多个双随机矩阵相乘的结果仍然是双随机矩阵,因此无论网络多深,跨层的复合映射都能保持稳定性。
第三是几何解释:Birkhoff多面体是所有排列矩阵的凸包,残差映射实际上是在对特征做凸组合,相当于一种稳健的特征融合机制。
![图片[8]-DeepSeek改造何恺明残差连接!梁文峰亲自署名,十年首次重大升级-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/01/20260101204751872-1767271671-44f4be888bb3703dde9ac435a579e9e1.png)
为了将任意矩阵投影到这个流形上,论文采用了Sinkhorn-Knopp算法。该算法先对矩阵取指数使所有元素为正,然后交替对行和列进行归一化,迭代收敛到双随机矩阵。
实验数据显示,这个近似解已经足够有效:在27B模型中,mHC的复合映射信号增益最大值约为1.6,与HC的3000形成了三个数量级的差距。
![图片[9]-DeepSeek改造何恺明残差连接!梁文峰亲自署名,十年首次重大升级-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/01/20260101204752910-1767271672-f82fb76822c6810b9e4ac6d66b40b472.png)
工程优化:从内核融合到流水线重叠
接下来进入DeepSeek的拿手好戏,工程优化环节。
扩展残差流宽度必然带来额外的内存访问开销,论文详细分析了每个token的内存读写成本:
标准残差连接需要读取2C个元素、写入C个元素,而HC需要读取(5n+1)C + n² + 2n个元素、写入(3n+1)C + n² + 2n个元素。
当扩展率n=4时,这是一个相当可观的增量。
团队为此开发了一系列基础设施优化,他们使用TileLang框架实现了多个融合内核,将原本分散的操作合并执行以减少内存访问次数。
针对Sinkhorn-Knopp算法,他们设计了专门的前向和反向内核,在芯片上重新计算中间结果以避免存储开销。
在流水线并行方面,他们扩展了DualPipe调度策略,通过将MLP层的特定内核放在高优先级计算流上执行,实现了计算与通信的重叠。
![图片[10]-DeepSeek改造何恺明残差连接!梁文峰亲自署名,十年首次重大升级-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/01/20260101204753128-1767271673-daf3b07d8268d32cf0578be207d4ebd4.png)
论文还给出了重计算策略的优化公式。对于L层的网络,最优的重计算块大小约为:
![图片[11]-DeepSeek改造何恺明残差连接!梁文峰亲自署名,十年首次重大升级-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/01/20260101204754449-1767271674-03425419adb36f0d653a516c2a27d869.png)
这个值通常与流水线阶段的层数相当,因此研究者选择将重计算边界与流水线阶段边界对齐。
实验验证:稳定性与性能兼得
论文在3B、9B和27B三个规模的MoE模型上进行了验证,扩展率n设为4。
在27B参数的MoE模型上,mHC展现出稳定的训练曲线,最终损失相比基线降低了0.021,同时保持了与baseline相当的梯度范数稳定性。
在下游任务评测中,mHC在BBH推理任务上比HC提升2.1%,在DROP阅读理解任务上提升2.3%。mHC在大多数任务上不仅超过基线,还超过了HC。
![图片[12]-DeepSeek改造何恺明残差连接!梁文峰亲自署名,十年首次重大升级-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/01/20260101204756396-1767271676-8070eb009f106eafe374a4c515e18d2d.png)
计算缩放曲线显示,mHC的性能优势在更高计算预算下仍然保持,仅出现轻微衰减。对3B模型的token缩放曲线分析表明,mHC的优势贯穿整个训练过程。
![图片[13]-DeepSeek改造何恺明残差连接!梁文峰亲自署名,十年首次重大升级-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/01/20260101204757172-1767271677-4568560690150b59b3da0a8ecb66e35c.png)
论文提到,内部的大规模训练实验进一步证实了这些结论,且当扩展率n=4时,mHC仅引入6.7%的额外时间开销。
![图片[14]-DeepSeek改造何恺明残差连接!梁文峰亲自署名,十年首次重大升级-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/01/20260101204758262-1767271678-9798bbdd6d8111e0529d6960391a89fb.png)
论文地址: https://arxiv.org/abs/2512.24880
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
量
<原文链接:https://mp.weixin.qq.com/s/CarJ2RFfonsx5QgK0R_EZQ













暂无评论内容