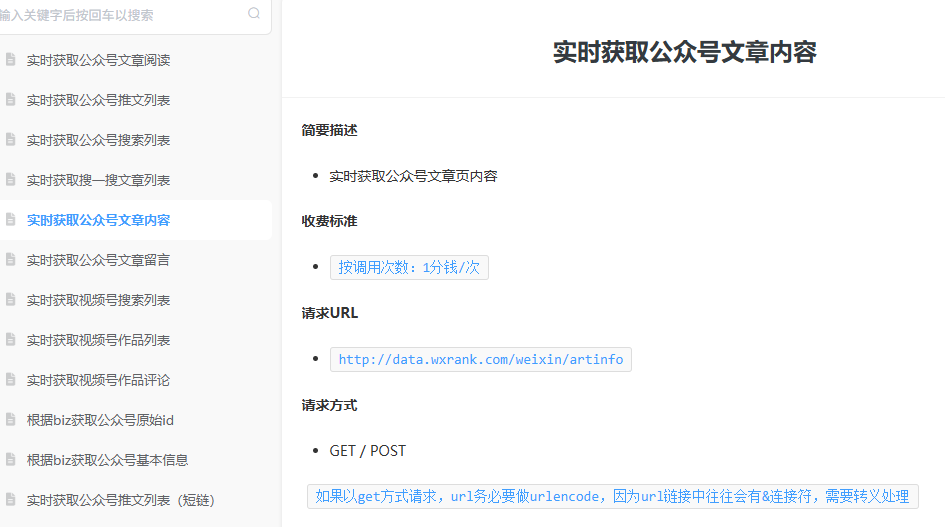
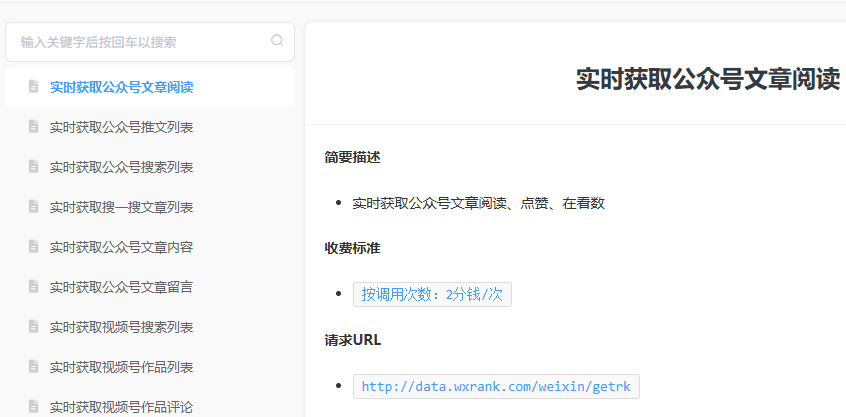
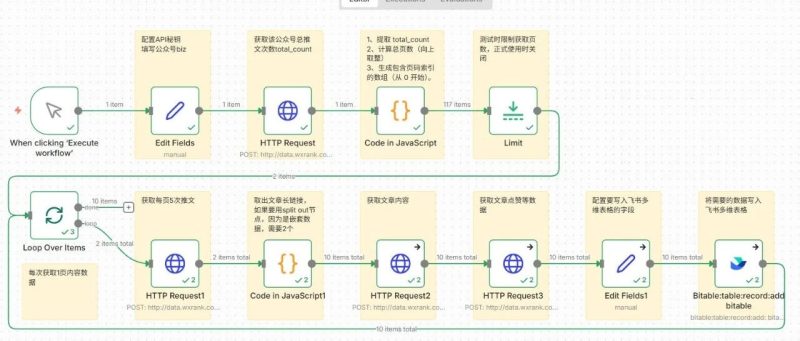
今天要分享的工作流,可以解决很多自媒体人的需求,快速批量将公众号历史文章及数据写入飞书多维表格,方便拆解分析。(这篇是前两篇的续篇,有些重复内容就不再细写了)整体工作流如下图(本例n8n版本为1.121.3)节点1,Manual Trigger,手动触发节点节点2,Edit Fields(简称set节点),用于设置工作流常用字段。这里需要配置微小榜API密钥(微信扫码登录,https://data.wxrank.com/?invite=o4zZB56DZNFnbSnxBUzFojA09oCY),关于此API介绍,详见永不枯竭的灵感池,把搜一搜变成自动选题库!第①部分。biz是公众号特有的字段,可以通过前面两篇工作流获取,也可以在浏览器打开某个公众号文章链接,查看网页源代码获取(快捷键ctrl+u,搜索biz,一般第一个就是)节点参数填写如下(这里以数字生命卡兹克公众号为例),点击下图中Execute step可单独运行本节点,出现右侧数据节点3,HTTP Request,这里通过推文列表接口获取总推文次数需要获取到的是total_count这个字段值(历史总推文次数)参数填写参考如下,执行后可以看到数字生命卡兹克历史总推文次数为581次(注:每次推文可以发布≥1篇)节点4,Code,这里提取出total_count的值,计算出总页数(每页5次推文,把total_count的值除以5,如果有小数点则进一,比如21除以5=4.2,表示有5页),然后生成页码索引的数组,后后面的循环节点使用。节点5,Limit,测试时使用,可以限制API请求次数,减少不必要成本如下图所示,Max Items填写2后,就将左侧的117 items限制为2了。节点6,Loop,循环处理,每次只获取一页内容数据(5次推文)注意:添加loop节点后,把Replace Me删除节点7,HTTP Request,这里仍然是用到推文列表接口,不过这次的目的是获取对应每页每篇文章链接,供后面的http节点使用。
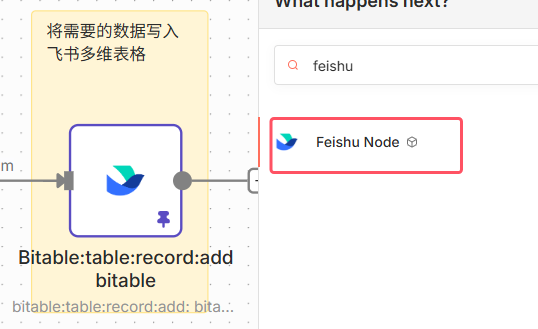
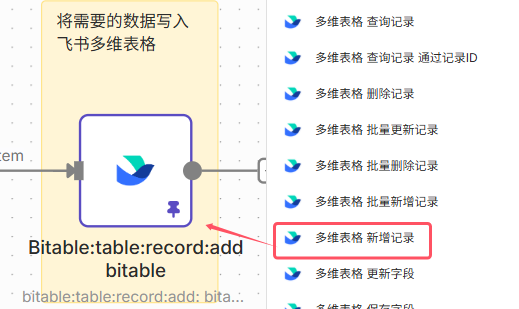
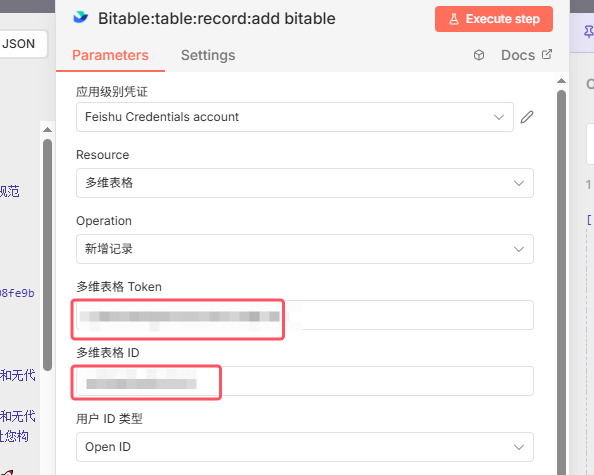
节点参数如下,目的是获取到art_url(文章链接)如果仔细观察前面一个节点给出的数据,会发现art_url被嵌套在数组里面,如果只是一个还好,但至少有5个链接分散在数组的数组的数组里,如果用split out节点,需要连续使用2个才能取出所需数据,所以这里用1个code节点直接取出,参数及效果如下对应API文档如下,可以获取阅读、点赞、在看、分享、收藏、留言数(需要传入comment_id,通过上一个节点获取到)节点11,配置要写入飞书多维表格的字段(比如文章链接,摘要,内容,各种数据)节点12如果想运行成功,还需先创建好多维表格,参考如下,注意点:不能是知识库创建的表格,需要在云文档-云盘处创建;n8n中配置的字段名和字段格式必须和多维表格内的完全一致,不然会写入错误最后,附上工作流和多维表格模板链接(https://pan.quark.cn/s/f289beeea990)。
好了,今天的内容就到这里,觉得有帮助的话,点赞收藏关注,我们下期见!原文链接:https://mp.weixin.qq.com/s/h9-yI1ffMVr52RDJDB5IYA

![图片[1]-n8n高阶玩法:一键下载公众号历史文章,阅读点赞数据全都有!-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/12/20251228003314438-1766853194-b949818b3aa5d69b23d62d6742cc5be3.png)
![图片[2]-n8n高阶玩法:一键下载公众号历史文章,阅读点赞数据全都有!-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/12/20251228003315720-1766853195-09d4faf2effed6ac195cddeb53bc0633.png)
![图片[3]-n8n高阶玩法:一键下载公众号历史文章,阅读点赞数据全都有!-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/12/20251228003316807-1766853196-bd4b3355bc200a899b4099d19e1ec496.png)
![图片[4]-n8n高阶玩法:一键下载公众号历史文章,阅读点赞数据全都有!-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/12/20251228003317978-1766853197-713042d4dddafadb5421cc5c78e580d0.png)
![图片[5]-n8n高阶玩法:一键下载公众号历史文章,阅读点赞数据全都有!-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/12/20251228003317875-1766853197-88a06d461812e7bbfec6900a520f9952.png)
![图片[6]-n8n高阶玩法:一键下载公众号历史文章,阅读点赞数据全都有!-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/12/20251228003318515-1766853198-0e6b613200eaa79653486a6c60edd887.png)
![图片[7]-n8n高阶玩法:一键下载公众号历史文章,阅读点赞数据全都有!-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/12/20251228003319283-1766853199-370b538fe55c9af3a611f190231e9b8d.png)
![图片[8]-n8n高阶玩法:一键下载公众号历史文章,阅读点赞数据全都有!-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/12/20251228003320127-1766853200-464bf4d0b422ae379c3ef729e1ccbd40.png)
![图片[9]-n8n高阶玩法:一键下载公众号历史文章,阅读点赞数据全都有!-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/12/20251228003320744-1766853200-888359392b847572b9d9dd7b1db1da2e.png)
![图片[10]-n8n高阶玩法:一键下载公众号历史文章,阅读点赞数据全都有!-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/12/20251228003321440-1766853201-4a745028922effea9e0677eeec2a4287.png)
![图片[11]-n8n高阶玩法:一键下载公众号历史文章,阅读点赞数据全都有!-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/12/20251228003322360-1766853202-fbe9848fb6a9d380787ec2286745b2a9.png)
![图片[12]-n8n高阶玩法:一键下载公众号历史文章,阅读点赞数据全都有!-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/12/20251228003323494-1766853203-52e74968007def054697eaf54b986763.png)
![图片[13]-n8n高阶玩法:一键下载公众号历史文章,阅读点赞数据全都有!-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/12/20251228003324975-1766853204-a5b32deb2a7ee37eeadd38b9def1a5d5.png)
![图片[14]-n8n高阶玩法:一键下载公众号历史文章,阅读点赞数据全都有!-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/12/20251228003324997-1766853204-65ccba8dc1bc9aa6aa76aae3221c470f.png)
![图片[15]-n8n高阶玩法:一键下载公众号历史文章,阅读点赞数据全都有!-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/12/20251228003325953-1766853205-198447a886bf4635fef833d0bb128923.png)
![图片[16]-n8n高阶玩法:一键下载公众号历史文章,阅读点赞数据全都有!-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/12/20251228003326417-1766853206-0d2807866aeaeb16a8761e4de72e264d.png)
![图片[17]-n8n高阶玩法:一键下载公众号历史文章,阅读点赞数据全都有!-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/12/20251228003327203-1766853207-1858df408197ce09f41c010689405a4c.png)
![图片[18]-n8n高阶玩法:一键下载公众号历史文章,阅读点赞数据全都有!-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/12/20251228003328775-1766853208-cb126fced46691d0be11637e95d24f66.png)
![图片[19]-n8n高阶玩法:一键下载公众号历史文章,阅读点赞数据全都有!-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/12/20251228003328531-1766853208-2d0dc1fedd1c7da9f5f786952d96d94d.png)
![图片[20]-n8n高阶玩法:一键下载公众号历史文章,阅读点赞数据全都有!-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/12/20251228003330654-1766853210-3b829ba90d791abe56b60c34cbf8505a.png)
![图片[21]-n8n高阶玩法:一键下载公众号历史文章,阅读点赞数据全都有!-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/12/20251228003331833-1766853211-774f0b06b38947673f86842618c00616.png)
![图片[22]-n8n高阶玩法:一键下载公众号历史文章,阅读点赞数据全都有!-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/12/20251228003331416-1766853211-6d73c4bb74529f522cd673f76666fcbb.png)
![图片[23]-n8n高阶玩法:一键下载公众号历史文章,阅读点赞数据全都有!-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/12/20251228003333858-1766853213-91585c9c64638e9359f5d8944045a8ee.png)
![图片[24]-n8n高阶玩法:一键下载公众号历史文章,阅读点赞数据全都有!-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/12/20251228003334641-1766853214-b0012b5eba13af198731d1145d258e61.png)
![图片[25]-n8n高阶玩法:一键下载公众号历史文章,阅读点赞数据全都有!-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/12/20251228003335450-1766853215-7a544f89ba393c328c80d7e5e9cf49e8.png)
![图片[26]-n8n高阶玩法:一键下载公众号历史文章,阅读点赞数据全都有!-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/12/20251228003336318-1766853216-3c9d219f99baf04ae4af8276ac80f8b0.png)
![图片[28]-n8n高阶玩法:一键下载公众号历史文章,阅读点赞数据全都有!-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/12/20251228003338686-1766853218-3118e4ccc16060c8c38b550c4811d127.png)
![图片[29]-n8n高阶玩法:一键下载公众号历史文章,阅读点赞数据全都有!-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/12/20251228003339500-1766853219-b51868f786377166a8977f4dfe649ad3.png)
![图片[31]-n8n高阶玩法:一键下载公众号历史文章,阅读点赞数据全都有!-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/12/20251228003341423-1766853221-eb22a498665ade0914cb767153fb0b15.png)
![图片[32]-n8n高阶玩法:一键下载公众号历史文章,阅读点赞数据全都有!-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/12/20251228003341130-1766853221-568b394855261cf4c975d4c7b87227fe.png)
![图片[33]-n8n高阶玩法:一键下载公众号历史文章,阅读点赞数据全都有!-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/12/20251228003343328-1766853223-f49b19a4d9fd594db763d607aa58e7f4.png)
![图片[37]-n8n高阶玩法:一键下载公众号历史文章,阅读点赞数据全都有!-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/12/20251228003346318-1766853226-7a276de98afa1d2a6e12abde6c49f3af.png)
![图片[38]-n8n高阶玩法:一键下载公众号历史文章,阅读点赞数据全都有!-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/12/20251228003347700-1766853227-d79d0000bdb2e532300a3ec7bd8bcf6b.png)
![图片[39]-n8n高阶玩法:一键下载公众号历史文章,阅读点赞数据全都有!-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/12/20251228003349546-1766853229-270eb116b55bec6da170f8699e8510cc.png)
![图片[40]-n8n高阶玩法:一键下载公众号历史文章,阅读点赞数据全都有!-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/12/20251228003350524-1766853230-89bb8dcc9ca4381a87735d103b03bc05.png)
![图片[41]-n8n高阶玩法:一键下载公众号历史文章,阅读点赞数据全都有!-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/12/20251228003350970-1766853230-f14c9ee5a65c54218ab26d5bee9ffbc4.png)
















暂无评论内容