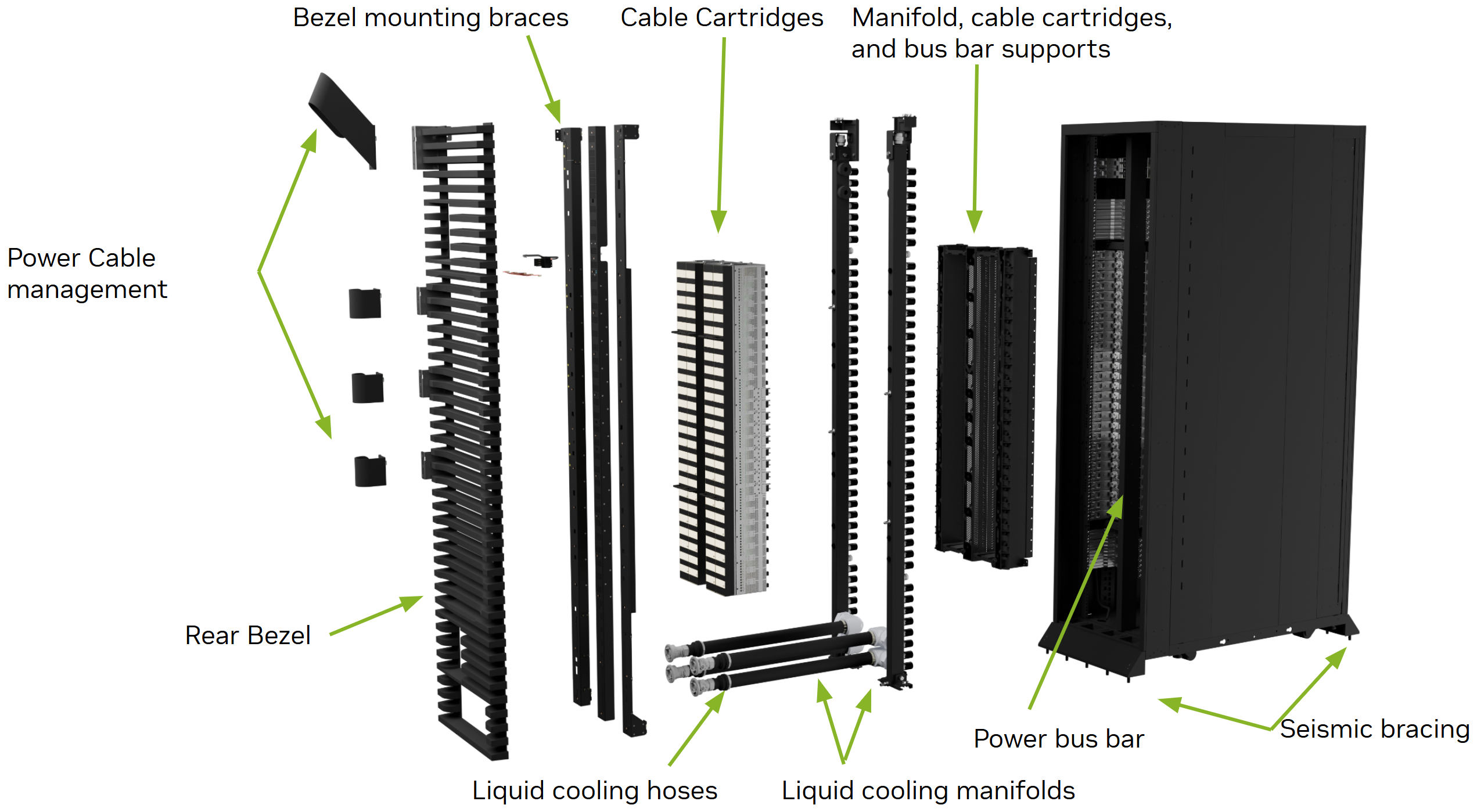
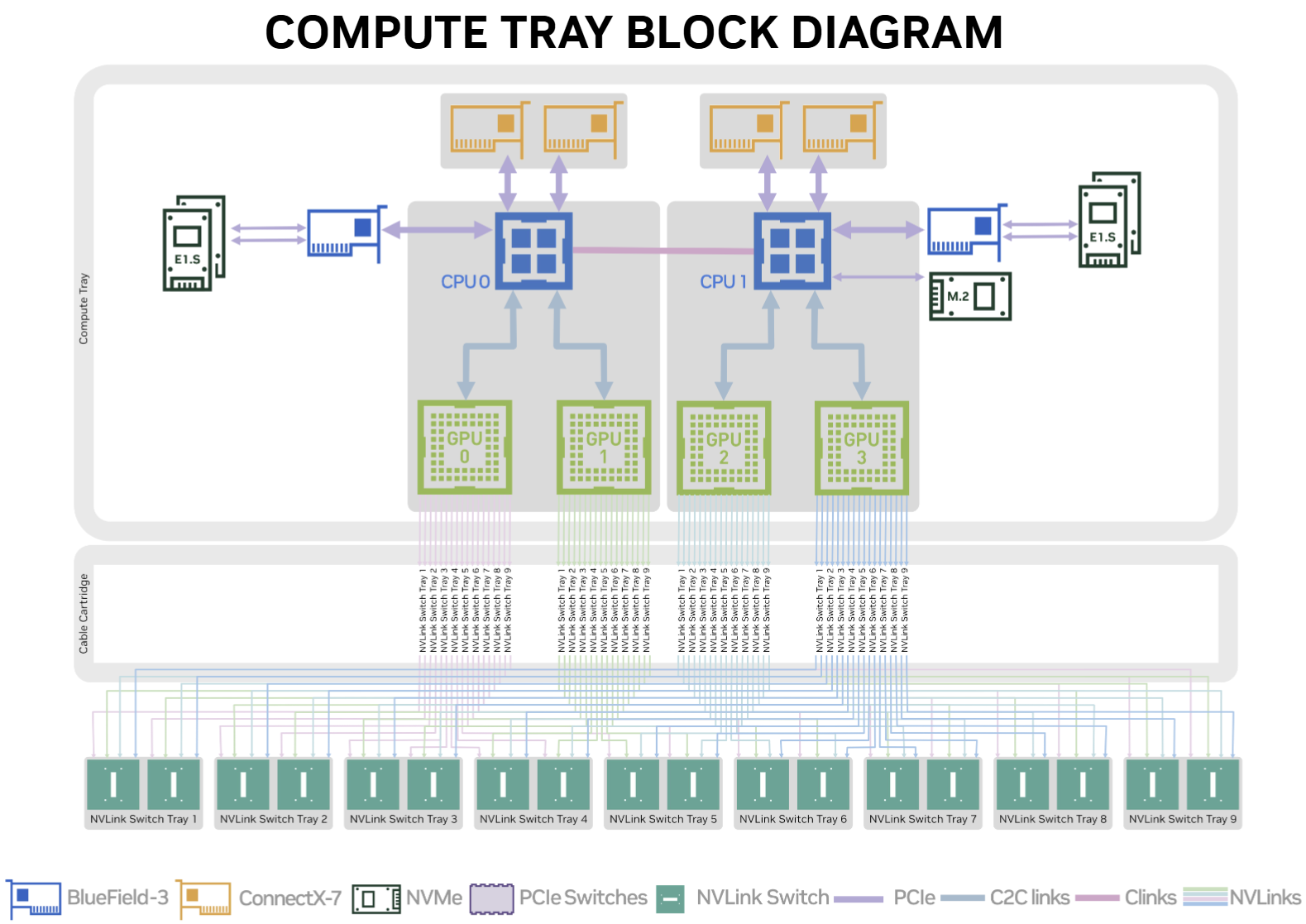
GPU超节点:硬件,软件,算法及应用演进昂的笔记5个月前更新关注私信05312在工作或学习期间、很多人应该都远程登录过服务器或机房,来运行一些高性能计算程序。随着时代的发展,这些任务也从一开始的仿真,图形学任务占多数变成了如今、以智能模型的开发,训练和部署为主。对于一般的智能计算任务,在单块或极少块GPU上就可以短时间的完成,但随着模型参数量提高的速度远快于单个芯片算力的提高(也就是我们常说的scaling law > 摩尔定律),以堆叠的方式进行算力扩展就变成了近年的主流趋势,这也是为什么全世界都在建GPU集群的原因,对于单块计算芯片的原理以及其如何使能神经网络等智能算法可以参见:揭秘AI芯片:CPU/GPU/NPU从计算到微架构本文将以浅显的方式介绍GPU集群,包括其物理拓扑和逻辑拓扑,在算法和应用层面是如何服务于深度学习时代的“小模型”到如今以transformer为主的”大模型“的。并且带领读者一瞥从A100时代开始到如今较为先进的NVL72 B200超节点的一些技术,看一下单GPU算力是如何以“横向”(scale-out)和“纵向”(scale-up)的扩展构成如今全世界最昂贵,且最智能的计算系统的。一、传统超节点我将含有GPU(通常是4块或8块)的服务器放进机柜里,并且机柜上有一些交换机(TOR交换机),同时有一些管理机柜,负责将这些交换机相连接,加上一些CPU服务器处理前端网络的请求,以及一些用于网络管理的流量组成一个由一组机柜构成的单个计算节点的方式称为传统超节点。这种方式的弊端很明显,首先机柜上的每一个性能单元(含有GPU的单元)都有网卡,CPU,其他的系统,用来进行机柜内的通信,并且机柜间的通信并未完全卸载到TOR交换机或者是管理机柜上,既导致空间的浪费,又导致管理的复杂和维护成本的上升。由上图可以看到,一个DGX A100服务器占6U的空间,到了H100占8U,而B100则占10U,那么要买多少个机柜,配多少电源管理,空调,水冷来维护这算力原来越大,但场地也越来越巨大的节点呢?在A100超节点中,一个DGX A100服务器由8块80GB的A100GPU构成,一个机柜如图所示可以放得下四个这样的服务器(简单的计算,单机柜2.4TB多的显存就足够进行如今大多数大模型的训练了,所以为什么要建万卡集群等在下文会有浅显的论述)。节点之间用IB相连,当年的带宽是200Gb/s,如今最新的IB网卡可以达到800Gb/s了。这个单个机柜堆叠GPU的过程我们称之为Scale Up,在机柜之前进行互联则形象的称为Scale out(在后续的NVL72等技术中可以看到scale up/out的方式有了质的变化)。由于交换机只有64个端口,所以网络一般都要进行分层,典型的物理拓扑就是胖树连接,这样可以保证节点之间的通信转发逻辑尽可能的卸载到管理服务器上,同时保证任两节点的跳数最小。也有其他的拓扑则是根据集群要服务的任务来决定的,但大概思路其实和在单块SIMT芯片上写程序所要考虑的事情是极其类似的揭秘GPU编程2:面向硬件的算法设计对于更大规模的拓展,则引入了一层core交换机(具体一个交换机连接几组其他交换机等可以在NV的官网找到,在此不浪费篇幅了)。而到了DGX H100/B100 等DGX SuperPod,思路是类似的,除了有时候可能把ToR挪到管理机柜等微小调整,整体思路变化不大。二、现代超节点既然要多个单体服务器在一个机柜上组成Scal Up单元,那为什么不只保留性能/算力部分,把诸如机内互联,网卡(甚至包括机柜内的通信)等都移动到一个地方,以最大限度的节省空间呢?这就是NVL36/72的设计思路在此之前首先要对机柜结构进行个性化的定制,传统的机柜的走线不再适用于这种较为“激进”的方式,如图所示,通过引入一个带铜片的背板NVL72节点可以将高度仅1u的18个计算单元加上9个交换单元塞进一个机柜里,NVSwitch在中间通过机架的背板进行GPU间的数据传输,这样一个机柜就可以容纳4*18=72块GPU!这也是为什么系统叫做NVL72(对于低配版则一个计算单元占2U,所以一个机柜只能放得下36块GPU)三、智能网卡上图是单个计算单元的硬件排布逻辑,可以看到,除了传统的CPU-GPU-NIC之外,在NVMe和CPU间加了一个蓝色的BlueField网卡,也就是集成了DPU的智能网卡,可以卸载一部分以太网的转发逻辑等的计算,让CPU专注于其他事情上。四、基础软件提到高性能集群的基础软件系统,可能读者会脱口而出SLURM,K8s等。的确,二者在很长的一段时间都统治了绝大多数GPU/CPU集群的日常管理,运维,调度,扩展等场景。但从本质上来说,在高性能计算系统上的任务编排与调度,是要深刻的结合硬件特性来进行的,同时还要考虑电源,故障恢复等问题,正因如此,基础开发都是必不可少的,这也是大规模系统的难点之一。分布式与社会但从应用的角度来讲,成熟的GPU集群管理系统又都会以相似的逻辑提供类似的功能,所以用Nvidia UFM为例,来说明基础软件系统的组成部分等如图所示,最基础的部分自然是交换机和网卡的驱动和相关转发逻辑的管理,在此之上的逻辑层则集成了SHARP等算法和其他协议(可以理解为根据网络拓扑自动进行算法选择,环路优化等)。到了应用层则可以适配虚拟化,容器化和其他服务(比如IaaS等)五、应用有关大模型的分布式训练/推理的文章已经有很多了,包括这些方式的排列组合甚至于如何对应到具体的GPU等细节,所以没有必要再进行重复描述了。除去开发新的算法外(这是截然不同的主题了),本人对于应用层面的难点的理解为:易用性与可拓展性的权衡。应用系统即不能太大:繁杂的细节会让一般的用户难以适应。要不然为什么大家不直接用c++写大模型,cuDNN难道不强大吗?而是要借助pytorch等前端框架。但系统也不能太小,不然对于一些新算法的设计,会带来工程实现上的困难,比如在不支持自定义算子的前端上显然就没办法做单GPU的性能优化了。同样的,大规模系统的通信优化是经久不衰的话题,有没有一种方法能够轻松的根据不同类型的计算负载使用不同算法,在必要的时候进行二次开发,并且和近年来兴起的智能网卡,软件定义网络(SDN)等技术更智能的结合,我想,应该是GPU集群管理的一个较为切实可行的方向(如今已经可以看到一些企业开发出了如,大模型预训练仿真软件等的原始系统了)。而除了服务于大数量级的用户外,GPU数量越高,则意味着在下一代模型开发的过程中,可以选择的技术就越多。比如:可以并行的进行结构搜索与超参数搜索,在这个过程中同时进行模型预训练和其他迭代等。在当下,不进行实验,是仍没有办法真正确定什么算法在各种意义上“效果更好”的。所以算力的堆叠,抛去战略意义,至少在如今的技术发展水平看来,仍然是必不可少的。同样的,如同在上篇文章结尾提到的,希望有朝一日半导体的光电器件技术能够成熟稳定的大范围应用。今年英伟达的量子计算芯片和NVQLink,也不禁让人联想到了在未来,或许可以构建一种超大范围极小通信开销计算系统的一丝可能性了。© 版权声明文章版权归作者所有,未经允许请勿转载。THE ENDAI 资讯喜欢就支持一下吧点赞12 分享QQ空间微博QQ好友海报分享复制链接收藏

![图片[1]-GPU超节点:硬件,软件,算法及应用演进-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/12/20251206231534117-1765034134-a390c2a99b482b2698d8c6fb1cae3102.png)
![图片[2]-GPU超节点:硬件,软件,算法及应用演进-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/12/20251206231536318-1765034136-682403efa53bb2d25c9f0553f0706ece.png)
![图片[3]-GPU超节点:硬件,软件,算法及应用演进-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/12/20251206231538234-1765034138-424fdb791cb7e81e6b174ae2f7c881b2.png)

![图片[7]-GPU超节点:硬件,软件,算法及应用演进-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/12/20251206231546318-1765034146-f0607a82829e418e801e8023a532d5f9.png)











暂无评论内容