



你好,我是袋鼠帝
今天,百度悄悄发布并开源了一款多模态文档解析模型:PaddleOCR-VL。
我看的第一眼,注意力全被它的参数量吸引了,0.9B。
![图片[1]-最强开源0.9B级OCR模型!本地Agent、知识库都有救了~-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/10/1761002918-f61bfc96308ac552dfbe73e48123e9ad.png)
这么小的参数量,意味着它对算力的要求极低,我感觉扔到手机上都能跑得动。
这对于很多想在本地环境,或者资源受限的设备上玩AI的朋友来说,简直是福音。
我之前做过不少AI知识库的业务,也用过很多OCR工具,那些OCR或多或少都会有一些问题。
要么出现阅读顺序混乱。在处理多栏排版的报纸、论文或杂志的时候,会把不同区块的文字拼接在一起,导致提取出的内容逻辑不通,就没法用。
要么表格解析一塌糊涂。一个清清楚楚的表格,它能给你识别成一堆丢掉结构的零散文字,还得你手动去重新整理。
另外就是公式识别,经常把各种数学公式,识别成一堆无意义的乱码。。。
现在,对于任何一个新出的OCR工具,我都是抱着期待又怀疑的态度。
于是,我很快就上手试用了PaddleOCR-VL。
没想到,这个0.9B的小鼻嘎,还挺不错。
比如我找了一张9月开的发票,上传给它识别
![图片[2]-最强开源0.9B级OCR模型!本地Agent、知识库都有救了~-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/10/1761002921-52b417b70250626fe52357c8acb8b328.png)
![图片[3]-最强开源0.9B级OCR模型!本地Agent、知识库都有救了~-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/10/1761002922-c5fae714293dec05b31d7b3a035df3e9.png)
结果,它完成的相当不错,不仅精准识别了上面的文字、数字,还给我输出了一个表格。
像这种双语合同也是轻松识别
![图片[4]-最强开源0.9B级OCR模型!本地Agent、知识库都有救了~-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/10/1761002922-428509aaec96c9c1c1f0d92084b8ce41.png)
![图片[5]-最强开源0.9B级OCR模型!本地Agent、知识库都有救了~-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/10/1761002923-07882cf883407cfe294061a9ae4c0621.png)
我又找了一些一些柱状图、折线图让它识别:
![图片[6]-最强开源0.9B级OCR模型!本地Agent、知识库都有救了~-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/10/1761002925-47e00938892462b515a13d25cc5f791b.png)
![图片[7]-最强开源0.9B级OCR模型!本地Agent、知识库都有救了~-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/10/1761002925-1e6edbef9b29e4aafa99cf124b30d268.png)
他竟然能识别出图表数据的关联关系,并转成一个markdown格式的数据
这两个小测试,瞬间就勾起了我的兴趣。我决定,得再给它上上强度。
不过在这之前,还是先给大家介绍一下PaddleOCR-VL到底是个啥?
我查了一下:
这款模型,来自百度飞桨的PaddleOCR团队。
这个团队,在OCR领域,相当强劲。
他们的PaddleOCR开源项目,在GitHub上是中国唯一一个Star数超过50k的OCR项目(现在57.2K了),累计下载量超900万,被超过5.9k开源项目直接或间接使用,绝对是业内的老大哥。
https://github.com/PaddlePaddle/PaddleOCR
![图片[8]-最强开源0.9B级OCR模型!本地Agent、知识库都有救了~-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/10/1761002926-a697a288337635260c8665f5a7e7fd2f.png)
这次的PaddleOCR-VL,可以看作是他们把OCR技术和最新的大模型能力结合起来的产物。
PaddleOCR-VL基于ERNIE-4.5-0.3B的语言模型训练而来,是文心4.5的最强衍生模型。
在最新的OmniDocBench V1.5这个国际权威榜单上,直接屠榜了。
![图片[9]-最强开源0.9B级OCR模型!本地Agent、知识库都有救了~-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/10/1761002926-253685f4384bc348cb2d17eceacb4b18.png)
把GPT-4o,Gemini-2.5 Pro这些国际大厂的顶级多模态模型,都甩在了后面。
在文本识别,公式识别,表格理解,阅读顺序这四个OCR的核心能力上,也全部拿了第一。
![图片[10]-最强开源0.9B级OCR模型!本地Agent、知识库都有救了~-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/10/1761002927-81b7cd1e1d3a08efbd4c74db9950edf6.png)
![图片[11]-最强开源0.9B级OCR模型!本地Agent、知识库都有救了~-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/10/1761002927-29919bc1b4892e9a9ef20de687984552.png)
OmniDocBench V1.5是目前国际上最系统、最具代表性的文档视觉语言理解基准之一,由OpenDataLab联合清华大学、阿里达摩院、上海人工智能实验室等多家机构共同建设。
覆盖了学术论文、财务报表、手写笔记等九大类真实世界里最复杂的文档场景,是目前行业里公认最全面、最难的文档理解评测基准之一
像GPT-4o、Gemini-2.5 Pro、Qwen2.5-VL这些国际主流的顶级模型,都把它作为官方的评测标准,来证明自己的文档处理能力。
![图片[12]-最强开源0.9B级OCR模型!本地Agent、知识库都有救了~-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/10/1761002927-f378e2fee82bb667e60d6998b77b2f6a.png)
昨晚才发布,今天PaddleOCR-VL就拿下了HuggingFace Trending全球第一
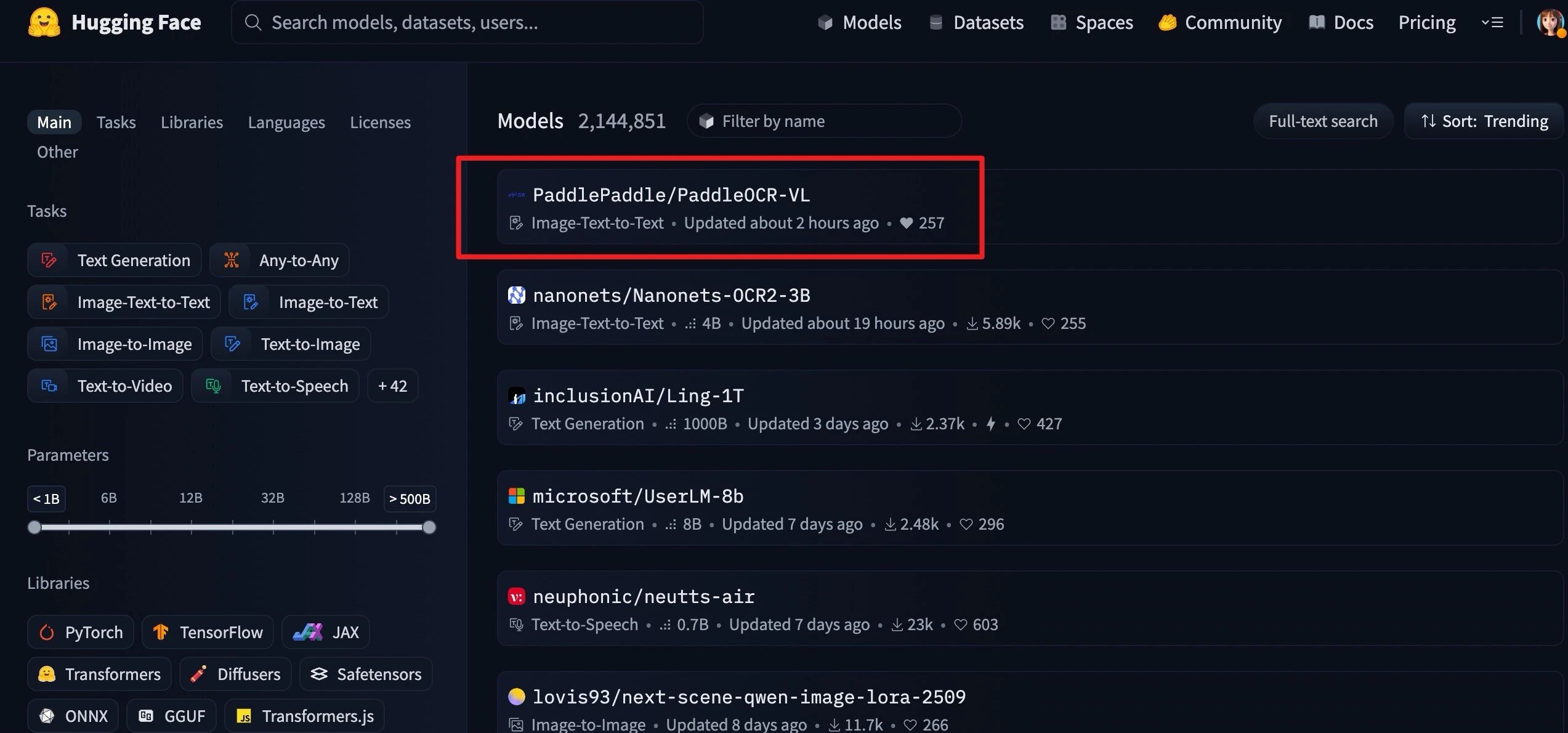
我觉得完全可以用它来拯救那些本地Agent的视觉能力。
以及解决本地AI知识库难以有效果处理多模态文件的问题。
而且这个成本是非常低的。
地址汇总 (方便大家直达):
huggingface:
https://huggingface.co/PaddlePaddle/PaddleOCR-VL
技术博客:
https://ernie.baidu.com/blog/zh/posts/paddleocr-vl/
技术报告:
https://arxiv.org/pdf/2510.14528
huggingface体验地址:
https://huggingface.co/spaces/PaddlePaddle/PaddleOCR-VL_Online_Demo
官方体验地址:
https://aistudio.baidu.com/application/detail/98365
不过,是骡子是马,还得拉出来遛遛才知道。
![图片[16]-最强开源0.9B级OCR模型!本地Agent、知识库都有救了~-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/10/1761002928-db336ca9fc78b9c5f1e5d1efa8b722f0.png)
![图片[17]-最强开源0.9B级OCR模型!本地Agent、知识库都有救了~-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/10/1761002928-abc57c1c40c6c33c837213f8b2d3ba42.png)
目前PaddleOCR-VL可以在官方的飞桨AI Studio里直接体验:
https://aistudio.baidu.com/application/detail/98365
>/ 医疗检测报告识别
我去年服务过一些医疗行业的客户(定制知识库和Agent),他们最大的痛点之一,就是如何让AI准确地识别和理解各种各样,格式五花八门的医院报告单。
当时我们用的是GPT-4o,但说实话,效果非常一般,经常出现识别错误和遗漏。
这个场景,绝对是刚需中的刚需。
我找了一张非常典型的检验报告单,这上面密密麻麻的检测结果是很多视觉模型的噩梦。
![图片[18]-最强开源0.9B级OCR模型!本地Agent、知识库都有救了~-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/10/1761002928-ac9cab84234d8efd4206aa7224373182.png)
下面是PaddleOCR-VL识别的检测结果
![图片[19]-最强开源0.9B级OCR模型!本地Agent、知识库都有救了~-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/10/1761002930-829cb6fddf44562d9a198c0c3c9113a1.png)
它把所有的项目和数值都准确地提取了出来,同时生成了表格的结构,更加清晰了。
而且非常稳定,试了很多次,每次提取的结果都不会变。
很多时候,稳定才是生产力
这个能力,对于医疗Agent的下游,比如报告解读,健康建议等,是至关重要的第一步。
>/ 古籍文字识别
为了考验它的文字识别能力,找了2张古籍的竖排版照片,而且是从右到左,从上到下的阅读顺序。
![图片[20]-最强开源0.9B级OCR模型!本地Agent、知识库都有救了~-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/10/1761002931-fd81cdd5ac0d5f60577c336deae19e75.png)
![图片[21]-最强开源0.9B级OCR模型!本地Agent、知识库都有救了~-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/10/1761002932-d502c4f23016cb7d456dd8cb69dc4f9c.png)
还是不错的,识别完全正确~
为了客观起见,我就突然想看看GPT5能不能搞定它。
有意思的是,GPT5直接弃权了。。。
并向我推荐了百度开源的PaddleOCR(前面说的57K Star的项目)
![图片[22]-最强开源0.9B级OCR模型!本地Agent、知识库都有救了~-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/10/1761002933-35168fa9da23155d9b6baa12965b256c.png)
完整对话这里看:
https://chatgpt.com/share/68f0e50b-c468-8001-95ad-c095edf9f28f
![图片[23]-最强开源0.9B级OCR模型!本地Agent、知识库都有救了~-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/10/1761002934-3dbd173aed5519aa08a2264fec1a66ab.png)
/> 复杂数学公式识别
复杂数学公式也一直是OCR领域的一大难题。
今年高考那段时间,我写了一篇DeepSeek R1参加数学高考的文章
那会儿高考都还没结束,网上搜到的数学考卷全是图片(没有文本)
本来我是打算搞个n8n工作流,全自动的让多个大模型参加高考,并自动打分。
结果搞了老半天,就栽在OCR这里,我记得我当时试了一堆多模态大模型API(包括GPT4o),效果都不理想,在大题那里老是把各种公式识别错误,,,直接进行不下去了。
你知道,抢热点需要非常迅速,所以我果断放弃了n8n的方案,采用了最原始的手动跑,所以就只测了DeepSeek R1这一个模型。
这次必须用PaddleOCR-VL试试
我找到了当时准备的高考数学试卷图片
![图片[24]-最强开源0.9B级OCR模型!本地Agent、知识库都有救了~-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/10/1761002934-b69056b49ddffb45b3768b74b353ff5f.png)
公式识别的相当准确
查看markdown的源文件,可以看到它是把这些公式识别并转为了LaTeX,这样丢给大模型去做题,他们也能轻松看懂这个公式。
![图片[25]-最强开源0.9B级OCR模型!本地Agent、知识库都有救了~-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/10/1761002934-b43ede61a74bbe40f38e3b565227a475.png)
对于那种带图的大题,它是这样识别的,它把图片转成了base64放在了markdown的源文件里面。
![图片[26]-最强开源0.9B级OCR模型!本地Agent、知识库都有救了~-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/10/1761002935-728940fabfeb696e818d90341f3e9ea4.png)
而这个markdown格式的带Base64图片的题,也可以直接发送给大模型做,完全满足我当时的需求。
![图片[27]-最强开源0.9B级OCR模型!本地Agent、知识库都有救了~-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/10/1761002936-013ccee3704d01250cb3a7498fa73fe9.png)
/> 化身「孤独的美食家」,轻松识别国外菜单
前段时间特别喜欢看《孤独的美食家》,吃饭的时候看,超级下饭~
我找了一张《孤独的美食家》里五叔吃过的饭店的菜单照片,还是多语菜单。
![图片[28]-最强开源0.9B级OCR模型!本地Agent、知识库都有救了~-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/10/1761002938-86bc498e4893029d0b0ac7fa00e5d14d.jpeg)
识别效果如下
![图片[29]-最强开源0.9B级OCR模型!本地Agent、知识库都有救了~-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/10/1761002939-5692f53e006ed18027b4797656db85be.gif)
看来PaddleOCR-VL的多语识别能力也不错。
>/ 识别图表
另外,它还可以识别一些图表,并转化为markdown格式的数据
这个功能是绝对的刚需,之前用过的一些OCR根本就不支持图表识别,或者说它们只知道把图表里面的字识别一下,根本不知道当中的关联关系。
>/ 识别表格类图片
表格类的图片就更不用说了
我的28条公众号文章数据表格截图,它可以轻松拿捏,把里面内容完整的识别成了一个规整的markdown表格。
其实我更看重的,是它0.9B这个参数量,带来的离线能力。
我之前接触过的一些国企客户,他们对数据安全的要求,是刻在骨子里的。
他们需要所有的AI能力,都能在自己的内网服务器上运行,绝对不能和公网有任何接触。
但他们又没有足够的算力预算,去部署那些动辄几百亿参数的庞然大物。
PaddleOCR-VL这种高性能的小模型,对于他们来说,就是绝对的刚需。
想象一下这些场景。
比如一个法务团队,需要审查上百份高度机密的商业合同。
他们可以把PaddleOCR-VL部署在内部服务器上,结合本地Agent,就能在完全断网的环境下,快速地提取所有合同的关键条款,进行比对和分析。
一个电力巡检工人,在深山里作业,网络信号非常差。
他可以用一个搭载了PaddleOCR-VL的平板电脑,对着设备上的仪表盘和工单拍照,AI在本地就能立刻完成识别和数据结构化,等回到有网络的地方再同步上传。
另外,还可以把PaddleOCR-VL,作为本地知识库平台(比如fastgpt)的视觉模型。
让我们的私有化知识库,也能方便的处理多模态数据。
可以试着把图片理解模型换成本地的PaddleOCR-VL
![图片[32]-最强开源0.9B级OCR模型!本地Agent、知识库都有救了~-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/10/1761002941-8be2b8cc90fede9c997bf3ecf9d539ca.png)
当使用的所有模型,和知识库都能离线运行时,才是完全本地化的AI知识库(私密性极高)
简单来说,仅有0.9B参数的PaddleOCR-VL之所以强大,源于一个非常聪明的设计:将复杂的文档解析任务分解为两个阶段:
第一步,先用一个轻量级的模型,PP-DocLayoutV2,去快速地扫描整个文档,把里面的文本块,表格,公式这些元素,一个个地框出来,并规划好正确的阅读顺序。
第二步,再把这些框出来的,一个个的小图片块,批量地,并行地,送给一个专门负责精读的PaddleOCR-VL-0.9B视觉语言模型,去识别里面的具体内容。
最后,轻量级后处理模块聚合两阶段输出,并将最终文档格式化为结构化的 Markdown和JSON。
这种先分后治的流水线作业模式,既保证了版面分析的准确性和稳定性,又极大地提升了识别的效率和速度。
![图片[35]-最强开源0.9B级OCR模型!本地Agent、知识库都有救了~-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/10/1761002941-715a5b1a507eaf93156c91af36f0453e.png)
它不像很多大模型那样,试图用一个模型,一口气吃成个胖子,同时完成版面分析和内容识别。这种搞法,虽然简单,但速度慢,成本高,还容易出错。
「最后」
体验下来,我对PaddleOCR-VL的感受是,务实,而且潜力巨大。
虽然它只有0.9B,但在文档解析这个专业领域,它的能力,确实强劲。
你给它输入图片或PDF,它给你输出结构化的Markdown或Json数据。
对,它其实是支持解析PDF的,不过线上demo还没支持(目前只支持上传图片),感兴趣的朋友可以安装到本地试试。
如果这篇阅读量超过8000,下篇教大家怎么本地部署,怎么把它接入fastgpt、n8n,拯救本地知识库和Agent。
把它强大的文档解析能力,集成到你自己的应用里。比如,你可以把它接入FastGPT,在创建知识库的时候,图片理解模型就选择PaddleOCR-VL。
后续官方可能也会推出MCP的使用方式,让它可以更方便地被各种本地Agent调用。
总的来说,我觉得PaddleOCR-VL的开源,为所有需要处理复杂文档的个人和企业,都提供了一个前所未有的,能在本地兼具性能和低成本的强大OCR工具。
值得一试~
能看到这里的都是凤毛麟角的存在!
如果觉得不错,随手点个赞、在看、转发三连吧~
如果想第一时间收到推送,也可以给我个星标⭐
谢谢你耐心看完我的文章~
<














暂无评论内容