


衡宇 鹭羽 发自 凹非寺
量子位 | 公众号 QbitAI
还在用Sora2做恶搞视频或表情包玩儿?快醒醒,国内AI视频玩家已实现弯道超车了——
开卷实时流式生成!
就是那种模型推理到哪儿,画面就生成到哪儿;想改剧情,直接暂停、改指令、视频重新走向。
换言之,Sora2能做的,它能做;Sora2做不到的,它还能做。
而这,才是和AI视频一起“创作”的未来式答卷——来自百度蒸汽机(文心专精版)。
![图片[1]-Sora 2 不够香了!这款国产 AI 视频模型已经能边看边生成,生成快还互动佳-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/10/1a9fafc78147ad183b82b3b74eac6382.png)
百度蒸汽机相信大家都已经不陌生了,5月份以黑马之姿闯入AI生视频赛道,初登场就拿下VBench-I2V全球榜一,全球首个实现中文音视频一体化的视频生成模型,首次实现多人有声视频生成……
而这一次升级的背后,是百度对AI视频生成领域的重新再定义。
当同行还卡在“生成10s稳定、连续的视频画面”时,百度已经率先实现“生成迅速、实时交互、无限续写”三件套:
只需一张图+一个Prompt,生成过程更流畅自然,短时间、低成本还能保持高质量。 支持实时交互,可随时打断视频生成进展,任意位置都能进行提示词改写。 打破视频生成时长限制,上传任意视频,就能续写成长篇影视级大作,还能实时预览视频内容。
此外,在百度蒸汽机,还能告别以往单向输出的数字人,定制1V1专属数字人,沉浸式体验数字分身互动;任意生成、创造全场景开放世界,无论是开拓新的游戏地图,还是爽玩全球旅游景点,百度这次,全都有。
![图片[2]-Sora 2 不够香了!这款国产 AI 视频模型已经能边看边生成,生成快还互动佳-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/10/a208a6903e7bd0294a0e79acd46d18f5.png)
正如蒸汽机曾经带来的技术革命,百度蒸汽机模型的此次更新也将标志着AI视频正式从短片段走向长篇叙事,从创意工具走向创意伙伴。
从“图生视频”到“边看边生”:行业首次流式生成体验
不过,当前主流的AI视频生成模型还处在Level 1,即使是最近风头最盛的Sora2,也普遍只能生成5~10秒。
坊间为此还出现了邪修鉴AI大法:遇事不决看时长!
而且要得到结果,短则30秒长则几分钟的生成阶段,必须老老实实等待。
期间做成啥样一概不知,生成完整视频后,无论是细节修改还是整支视频大调,都没法实时调整,只能重来一遍,更谈不上有什么“交互感”。
这个过程不仅耗时长,而且成本惊人,想要实时交互修改基本上是不可能的。
这对短视频生成而言,还算够用,但放到长视频显然不够看,即使勉强用首尾帧技术拼接拉时长,但视频质量低下、细节粗糙,缺乏连贯性。
![图片[3]-Sora 2 不够香了!这款国产 AI 视频模型已经能边看边生成,生成快还互动佳-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/10/e0c124c2146f4f312cce5dd564e2abe2.png)
百度蒸汽机的出现,则填补了这一领域的空白,让AI视频提前进入了边看边生、实时共创的全新阶段。
不仅生成速度快人一步,生成质量也快到飞起。
首先是生成模式上,既能I2V图生视频,又能V2V视频生视频,双线齐发力。
图生视频将操作门槛降到最低,摒弃传统的多图+多指令模式,只需最基础的一张图和一个简单指令,就能生成长视频。
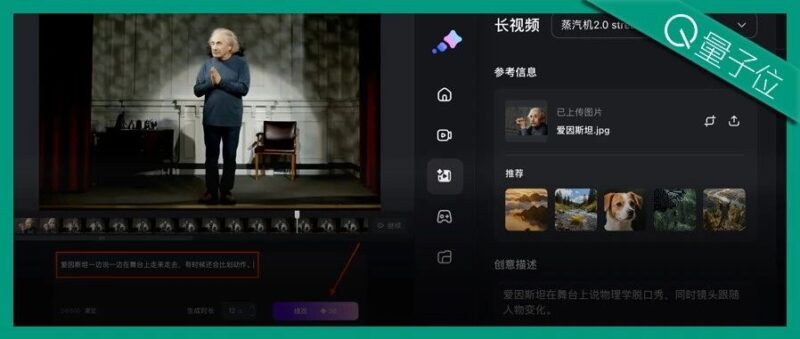
比如说我们先进入百度绘想平台,选择“长视频”功能入口,上传一张爱因斯坦的形象照,输入Prompt:
爱因斯坦在舞台上说物理学脱口秀,同时镜头跟随人物变化。
![图片[4]-Sora 2 不够香了!这款国产 AI 视频模型已经能边看边生成,生成快还互动佳-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/10/d08c0af4d9b994d52de4ade00847d6d1.png)
注意这里还要选择10-60秒的时长,一般默认20秒。
![图片[5]-Sora 2 不够香了!这款国产 AI 视频模型已经能边看边生成,生成快还互动佳-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/10/5a1ff3c7e76023c89e70a1243c955f8c.png)
视频开始生成后,可以在旁边的任务结果区实时看到当前生成进展。
![图片[6]-Sora 2 不够香了!这款国产 AI 视频模型已经能边看边生成,生成快还互动佳-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/10/afb33b394c6c888be68492be71c6e2f5.png)
一旦发现不满意,立马点击“续改”按钮中断生成,将视频帧拖至目标位置,重新下达新的指令,例如这里我们将让爱因斯坦的动作更丰富一些,让他一边说一边还会比划动作。
一个小tips:
每12秒,生成任务会自动暂停一次,此时需要用户自己手动选择继续生成or就此结束嗷~
![图片[7]-Sora 2 不够香了!这款国产 AI 视频模型已经能边看边生成,生成快还互动佳-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/10/1997e2c452b23c001d2e1a219df0a40d.jpeg)
下面请欣赏一段新鲜出炉的爱因斯坦的默剧版脱口秀。
BTW,如果你不想要看无声短片,可以选择蒸汽机2.0有声版。
不过相对应的,最长时长就需要打一丢丢折扣(5~10s)。
好好好,教科书里的人物都能活过来讲脱口秀了,物理学原来可以这么有趣!
要是我读书的时候有它,也不至于回回物理考零昏(doge)
而百度蒸汽机的视频生视频,本次更新端上来的全新玩法:
同样是在长视频入口进入,首先需要上传一个时长在2秒到60秒的视频,我们这里使用的是上次没做完的哈利波特的太极拳文艺汇演视频。(咳咳)
原视频be like:
期间依旧是可以实时查看或修改视频内容,不过需要注意的是,有且仅有2个视频可以同时生成。
最终续写下来,效果也是纵享丝滑~
(这下麻麻再也不用担心以后小组作业队友做一半跑路了555)
另外,蒸汽机在开放世界上也表现优异,例如我们让它来生成一段月球漫步。
还可通过WASD+鼠标控制视角,在月球上自由探索。
Nice!下次旅游旺季,不用出远门人挤人,在家就能环游世界,计划通✅
不过言归正传,蒸汽机到底为啥一下就Next level了?还得是背后的技术升级立大功。
“边生成边互动”的AI视频体验,如何炼成?
当下,包括Sora 2在内的AI视频工具,都在朝更长、更稳、更真实、更清晰突破。
但有一点似乎被大多数玩家忽视了:
目前,“生成→等待→反馈”的生产流程,其实一直停留在AI单向输出的阶段。
背后原因主要还是归结于行业主流方案是采用基于Transformer架构的扩散模型。
受限于Transformer架构的二次计算复杂度,主流AI视频生成模型计算开销随生成时长呈平方级增长。也就是说,需要生成的视频时长越长,对GPU显存与计算效率的要求就更高。
一方面成本直接拉爆,另一方面推理效率也难以达到较高水准,所以难以实现实时生成与交互能力。
![图片[8]-Sora 2 不够香了!这款国产 AI 视频模型已经能边看边生成,生成快还互动佳-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/10/a464b8fdf22fc6ff7f39f96be296b637.png)
而迭代后的百度蒸汽机,已经实现了“用户被动接收”向“AI与用户共同创造”的转变。
在蒸汽机这里,AI视频生成过程本身就是开放的——
视频不是一口气生成完毕,而是流式呈现。
模型推理是什么进度,用户就能看到对应时长的画面。
![图片[9]-Sora 2 不够香了!这款国产 AI 视频模型已经能边看边生成,生成快还互动佳-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/10/bf0c2da88e3fdf8c5e281e5095e318cf.png)
生成过程可随时打断。
生成中途,用户要是灵感突发想改点什么,一句新的prompt就能实时生效。
![图片[10]-Sora 2 不够香了!这款国产 AI 视频模型已经能边看边生成,生成快还互动佳-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/10/b9d80112911eae16e0ab66c5195988c3-scaled.png)
不满意前一段内容?还可以拉回修改,重新接上。
一句话总结,百度蒸汽机生成AI视频,已经进入能配合你反悔的Next Level,一切都不必从头再来。
整个过程像是创作者在电脑前观摩AI创排导演一支视频短片,随时可以以“导演”的身份喊卡,调整细节,修改剧本。
从这个角度来看,百度蒸汽机突破的不只是长视频生成的技术瓶颈,而是AI视频的整个创作范式,是一次对AI生成流程的重新定义——
AI视频生成,终于进入“你说我做,随时可改”的时代。
![图片[11]-Sora 2 不够香了!这款国产 AI 视频模型已经能边看边生成,生成快还互动佳-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/10/33286420d78a4e4ce9eadb57376e1c23.jpeg)
为了让模型学会边输出边协作,百度蒸汽机在模型层面,从架构到底层推理流程,几乎做了一次彻底重构。
首先是模型架构层面,百度蒸汽机通过引入自回归扩散模型(Autoregressive Diffusion Models),采用基于流式滑窗的自回归扩散架构,来实现低成本无限外推和实时生成。
不仅有阶梯独立噪声构造,还进行动态缓冲区管理,让模型能同时处理模糊草图、半完成帧及高精度画面,最终实现“边生成边调整”的实时交互生成流程。
其次,为了解决训推过程中累积误差和衰减问题,百度蒸汽机引入了噪声重注入和历史帧扰动增强机制,让它不仅听得懂指令,还能应对突发调整。
所谓噪声重注入,就是在训练时故意加入真实工作中可能遇到的“噪声”或偏差,让模型在模拟真实复杂环境的过程中学会更稳、更准地生成结果。
历史帧扰动增强,则是让模型学着自己生成过程中的问题并自己修正以应对变化。
第三,在生成画面的一致性方面,百度蒸汽机在引入锚点帧引导保障全局记忆的同时,还引入历史参考帧保障连续生成。
最后需要提到非常重要的一点,就是百度蒸汽机基于自回归扩散架构,突破高压缩比生成技术,大幅提升扩散模型流式推理性能,保障效果和效率的极致平衡。
通过窗口attention优化和模型蒸馏,用户使用百度蒸汽机生成视频时,推理延迟被压缩到几乎实时,几乎不会有“等”的感觉。
技术落地、生态生长,推动AI内容创作进入共创时代
像百度蒸汽机这样,全流程可控、可打断、可改写的实时共创,让AI视频生成变得参与性更突出,打开了AI内容创作的新的可能空间。
于是问题也随之升维。
拥有实时生成能力之后,AI视频模型能否真正走进创作现场、嵌入真实生产流程?因为对AI创作工具来说,真正的考验场在创作场景和生产链条上。
生成能力再强,实时互动感再强,如果无法走进创作现场,也只是(实验室里的模型)温室里的花朵。
回顾百度蒸汽机的迭代路径,可以清晰看到它的演进节奏,看到一条从底层技术突破,到产品形态重构,再到全链条生态落地的路径:
- 5月,百度视频生成模型以总分89.38%的成绩,登上海外权威视频生成评测榜单VBench-I2V图生视频榜全球第一,率先证明了自家视频生成的技术力;
- 7月,百度发布自研音视频一体化模型MuseSteamer(百度蒸汽机背后模型),首创中文音画协同生成能力,支持画面、语音、配乐一体生成,真正突破“画完再配音”的AI短片分离流程;
- 8月,百度蒸汽机音视频一体化模型完成重大升级,在业内首次实现多人有声视频生成,并全面开放Turbo、Pro、Lite等多个版本,打通C端与B端应用通道;
- 9月,发布“通用AI长视频生成”功能;
- 10月,百度蒸汽机让AI视频正式进入实时交互时代,视频生成不再是一次性产物。
可以看到,短短5个月内,百度蒸汽机实现了从图生视频到音画一体生成,再到实时互动+无限流式生成的演进。
![图片[12]-Sora 2 不够香了!这款国产 AI 视频模型已经能边看边生成,生成快还互动佳-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/10/1be0ca195f8e77e35eb99d35c877a755-scaled.png)
这样的底层能力重构,首先直接改变的是C端普通用户的创作方式。
无需专业视频剪辑经验,只需上传一张图片并输入一句prompt,用户就能在平台上生成一段可实时预览、随时修改、随时续写的AI视频。
最大程度告别屡次三番抽卡的烦恼,同时真正实现使用0门槛。
另一边,迭代后的新技术更能推动AI视频能力快速向导购、直播、教育、影视制作等商业和应用场景延伸的需求。
这一切,让百度蒸汽机不再只是一个模型产品,而是新型创作平台与交互接口的起点。
![图片[13]-Sora 2 不够香了!这款国产 AI 视频模型已经能边看边生成,生成快还互动佳-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/10/1be5edcc28e5577770852d03e5f8125d.gif)
所以说,别再沉迷于用Sora 2做各种meme和表情包了!
真正让AI视频迈入下一阶段的技术和应用,正在中国发生。
作为国产AI视频工具代表,百度蒸汽机不仅在技术架构、生成质量上持续演进,更在实时性与交互性这两个决定未来创作形态的关键点上,率先跨出一步。
这不仅是AI视频从片段式生成迈向连续叙事的标志性时刻,也是AI内容创作从独演走向共创的重要起点。
看看现在吧——AI视频的下一阶段,不只是高清,不只是更长,而是实时、可交互、效果出众、人人可用。
而百度蒸汽机,已经率先抵达新阶段的竞赛场。














暂无评论内容