



![图片[1]-科学智能数据库Sciverse发布,让科学数据成为Agent可调用的资源-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/04/20260408005104561-1775580664-13e92fc3e4fdea76d6b47c541746ccd9.gif)
当前,科学数据与模型训练需求之间仍然存在明显鸿沟——科学数据天然具有多模态、强专业性和高复杂度等特征,难以直接进入模型训练流程。
为解决上述问题,上海人工智能实验室(上海AI实验室)在第二届浦江AI学术年会上,发布了科学智能数据库Sciverse。其包含通识(Sci-Base)、跨界(Sci-Align)、高阶(Sci-Evo)三层体系,可满足从科学通识底座构建到多模态数据对齐,再到高阶推理及探索能力训练的不同数据需求。
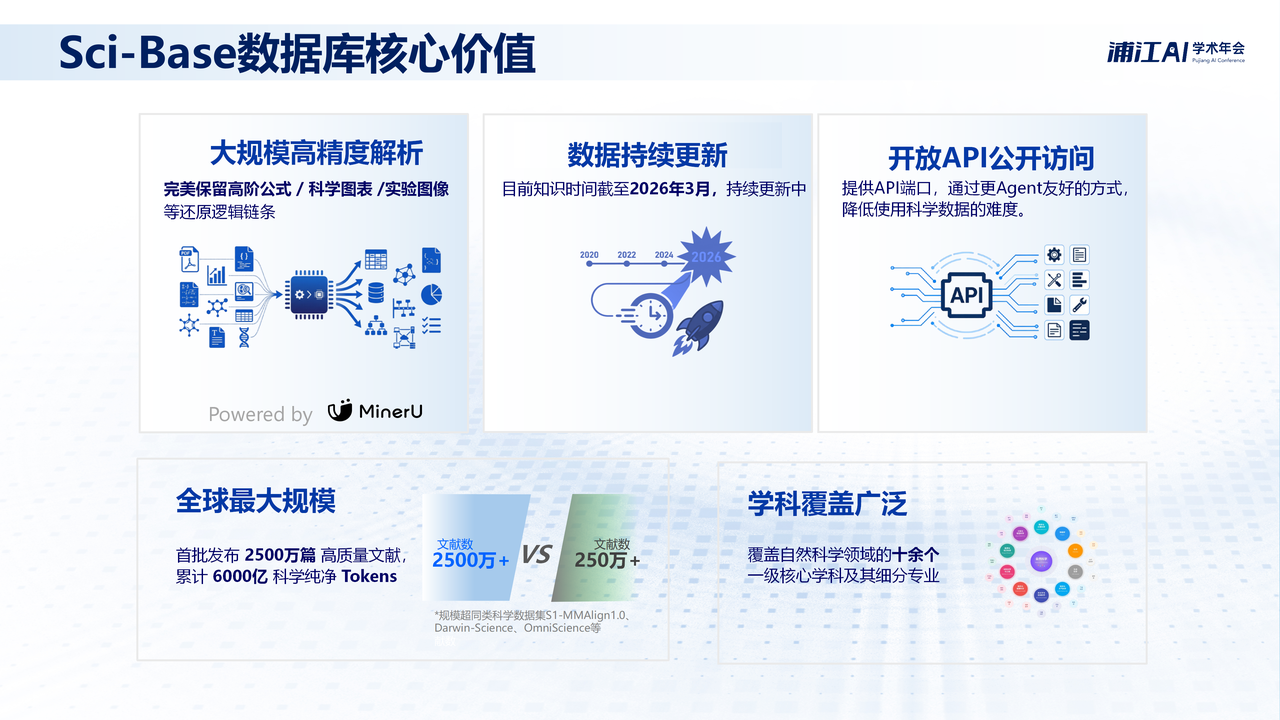
运用智能文档解析引擎MinerU,上海AI实验室开放了2500万篇公开可获取的文献,沉淀出6000亿词元,囊括了过去数十年全球主流开放科研成果,覆盖我国高等教育体系中自然科学领域的10余个一级核心学科及其细分专业。此外,Sciverse还可实现自动更新并通过API与Skill对外提供服务,为科学大模型训练、科学研究提供及时、不间断的数据支撑。
该项目正处于建设关键期,未来将建成100PB级超大规模科学智能数据库,覆盖我国研究生学科全体系,为科学发现提供高准确度、强时效性的AI Ready数据基座支撑。
Sciverse官网:https://sciverse.opendatalab.com/
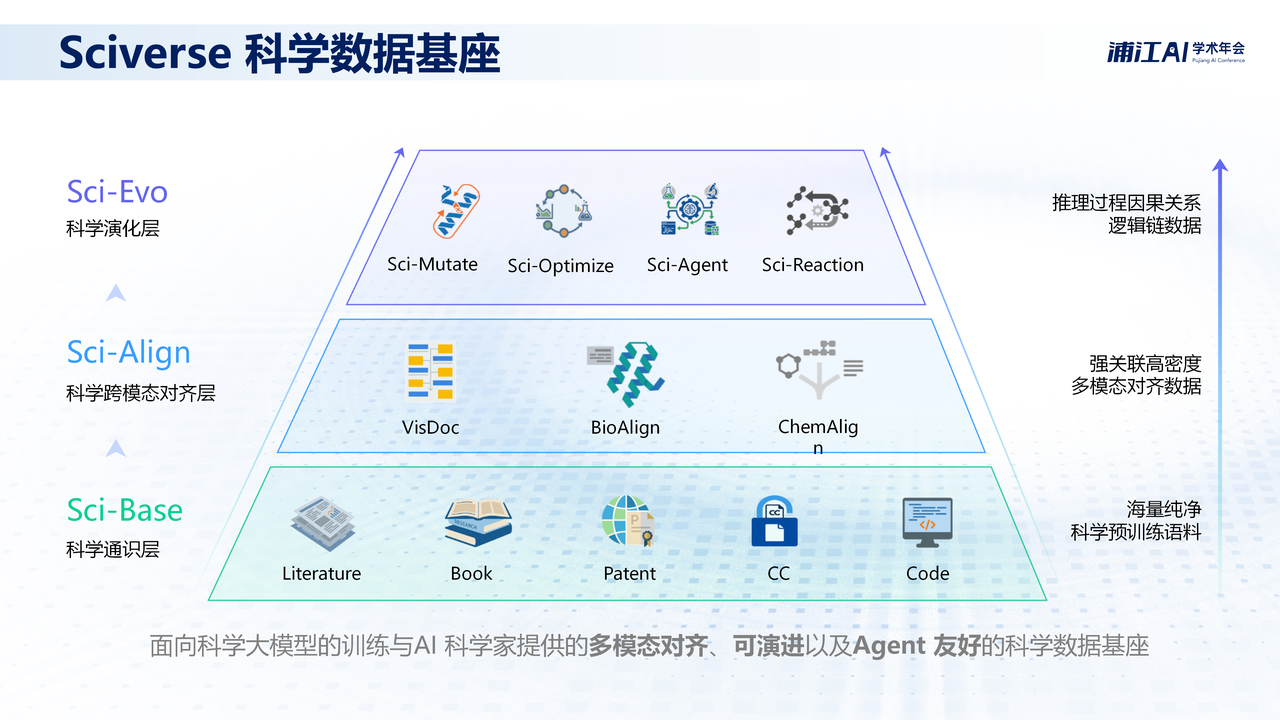
Sciverse架构图
Sci-Base:2500万文献重构,打造“Agent-Friendly”的科学数据底座
作为Sciverse的底层科学通识层,Sci-Base构建了目前全球规模最大的通用科学数据底座。Sci-Base所承载的是科学数据中最具共性、也是最基础的一类数据——以科研论文、教材与学术著作为代表的通识性科学文献。这类数据并不稀缺,几乎所有科研机构与团队在日常工作中都会接触和积累。然而,长期以来,这些数据分散于不同来源,标准不统一、结构不一致,导致大量重复的数据收集、清洗与解析工作被不断重复投入。
Sci-Base的核心价值,并不在于重新创造这些数据,而在于将这类基础性数据系统性地“做全做透”。通过对大规模科学文献的统一解析、结构化重构与持续更新,科研团队将原本分散的数据整合为一个完整、可用、持续演进的科学数据底座,使科研人员与开发者无需再从零开始处理底层数据。
依托MinerU智能文档解析引擎,Sci-Base已对超过2500万篇开放获取(OA)科学文献与书籍进行了高质量数字化重构。在此过程中,科研团队对复杂数学公式、化学反应式以及高精度图表进行了深度结构化处理,将原本碎片化、难以直接利用的文档内容,转化为超过6000亿个具备AI Ready特性的高质量Tokens,为模型训练与推理提供可直接使用的科学数据基础。
在规模之外,Sci-Base的价值同样体现在其系统性的知识广度上。其内容横跨自然科学领域的主流研究方向,对应我国高等教育体系中的核心学科结构,覆盖我国高等教育体系中自然科学领域的10余个一级核心学科及其细分专业。
在知识时效性上,Sci-Base同样具有明显优势,其数据已更新至2026年3月,而目前业界主流先进大模型的知识截断日期多停留在2025年,甚至更早。例如,Claude 4.6的知识截止至2025年8月,Grok 3/4为2024年11月。相比之下,Sciverse能为科学大模型训练和科研应用提供更及时、不间断的数据支撑,保证数据不过时。
更重要的是,Sciverse正在推动科学数据从“面向人类阅读”向“面向模型与智能体使用”转变。一方面,通过大规模、高一致性的深度解析,使数据能够直接用于科学大模型训练与推理;另一方面,对外提供API与Skill服务,使科学大模型训练与AI科学家应用可以像调用搜索引擎一样,直接获取结构化、可用的科学数据与文献信息。
在这一模式下,科研团队无需再自行寻找数据源、重复解析文献或反复验证数据质量与时效性。基础数据处理的成本被显著降低,研究者可以将更多精力投入到真正的科学问题与创新本身。
Sci-Align:破解多模态数据割裂,让大模型全方位理解科学数据
多模态对齐数据是训练科学大模型的关键基础,但也是最为稀缺的一类数据。与通用文本或图像数据不同,科学数据天然具有更高的模态复杂度和知识专业度:同一个科学问题,往往同时涉及结构、图像、公式与文本等多种表达形式。
例如,在生命科学中,一条蛋白质序列对应一维序列、三维结构,同时还需要通过文本描述其功能与作用机制;在化学领域,一个反应既可以通过SMILES等结构化符号表示反应物与生成物,也常以反应路径图等形式呈现,并辅以文字说明其反应条件与机理。为破解这类问题,科研团队打造了多模态科学数据对齐层Sci-Align。
在生命科学方向,Sci-Align中的高质量蛋白质注释数据集聚焦“序列—结构—功能”这一核心映射问题,构建了覆盖超过1800万条蛋白质序列的高质量注释数据,是当前规模领先的蛋白多模态对齐数据之一。相较于传统蛋白数据库多以单一序列或结构信息为主,该数据集不仅包含序列本身,还整合了结构信息与多维度功能注释,并通过融合主流生物信息学工具的分析结果,实现了不同模态之间的统一表达,使大模型能够在同一数据体系下理解蛋白质从结构到功能的完整关系。

在化学领域,Sci-Align中的大规模有机化学反应数据库依托MinerU文档解析引擎,对海量有机合成专利进行了结构化重建,覆盖超过百万篇USPTO与EPO专利,广度层面已达到与SciFinder、Reaxys相近的水平。数据库围绕单条反应构建了18个信息维度,整合反应物质、条件参数、操作流程等关键信息,并实现与原文的精准溯源,使数据具备更高的信息完整性与可用性,从而有效支撑科学大模型在有机化学方法学与逆合成路径规划等方向的深入研究。

作为Sciverse架构的科学演化层,Sci-Evo面向更高阶的数据形态,重点补足当前科学大模型在推理逻辑、实验过程与试错机制等方面的能力短板,通过引入第一性原理推导、实验设计路径及反思修正等信息,推动模型从“学习已有知识”向“具备推理与探索能力”转变,为科学智能体的发展奠定数据基础。
在此方向上,Sciverse也在持续推进开放生态建设。诚邀各学科领域专家、高校及科研机构,共同参与Sci-Evo推理链数据、Sci-Align对齐数据与的共建,一起推动科学智能的数据边界。
![图片[6]-科学智能数据库Sciverse发布,让科学数据成为Agent可调用的资源-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/04/20260408005124770-1775580684-c3367ab7b922cd909d739325c6dfa4e9-scaled.png)
![图片[7]-科学智能数据库Sciverse发布,让科学数据成为Agent可调用的资源-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/04/20260408005129170-1775580689-b6364e4783aa86ce0bb0aa20878d315d.png)
![图片[8]-科学智能数据库Sciverse发布,让科学数据成为Agent可调用的资源-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/04/20260408005132304-1775580692-1a933e1913627c5b3c2e61b791ae6a9f-scaled.png)
![图片[9]-科学智能数据库Sciverse发布,让科学数据成为Agent可调用的资源-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/04/20260408005136485-1775580696-b968df60a79033874efe248d3b64d8f7.png)
![图片[10]-科学智能数据库Sciverse发布,让科学数据成为Agent可调用的资源-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/04/20260408005139369-1775580699-30b2fbb8d7e8996cb644ecc1e8d713dd-scaled.png)
<原文链接:https://mp.weixin.qq.com/s/C5otOrUXM3yrOnsqDaHMSw








暂无评论内容