![[CVPR 2024]从 CT 到超声,一套代码全搞定?MADGNet 的通用化之路-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/03/20260304195820365-1772625500-1d541e89e83a0b2cc6da58dade0628f6-800x340.jpeg)



[CVPR 2024]从 CT 到超声,一套代码全搞定?MADGNet 的通用化之路

医疗影像分析领域经常面临一个“头疼”的问题:同一台机器在不同医院(不同域)、甚至不同成像设备(不同模态,如 CT、超声、内窥镜)下采集的图像,差异巨大。这就导致很多在实验室表现完美的模型,一进医院就“水土不服”。来自韩国仁荷大学(Inha University)的研究团队带来了他们的方案——MADGNet。本文对模型思想和代码进行解读。
1.研究背景
在医疗图像分割中,深度学习网络(如经典的 UNet)已经立下了汗马功劳。但现实很残酷,现有的模型往往存在两大痛点:
(1) 模态敏感(Modality-sensitive): 针对 CT 训练的模型,很难直接用到超声图像上。因为不同模态的图像,其频率特性(纹理、边缘)和尺度特性(病灶大小)完全不同。
(2) 信息丢失: 许多模型为了提升性能会采用“深监督(Deep Supervision)”和多任务学习,但在将低分辨率特征图强制上采样回原始尺寸时,往往会丢失精细的边界信息,导致分割结果“毛糙”。
这篇论文的核心目标就是:如何构建一个模态无关(Modality-agnostic)且具备强泛化性(Domain Generalizable)的网络?
2.核心创新
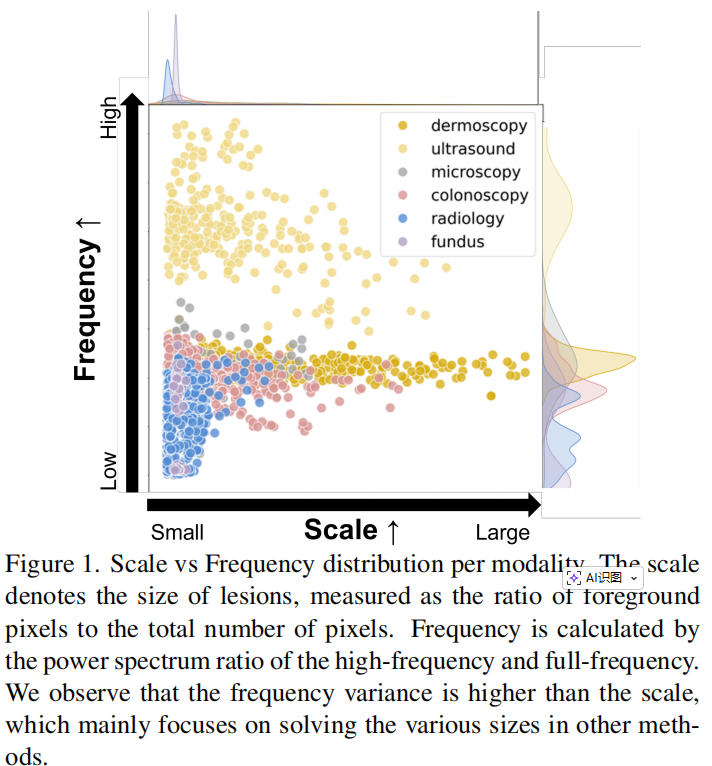
研究者们通过观察发现,不同模态影像在“尺度(Scale)”和“频率(Frequency)”两个维度上展现出了极高的方差。
(1) 尺度(Scale): 代表了病灶(如肿瘤、息肉)的大小比例。 (2) 频率(Frequency): 反映了组织的纹理和边缘信息。
MADGNet 的核心创新就在于它不只盯着目标的“大小”看,还学会了分析目标的“频率”特征,并将两者有机结合。
3.模型方法深度解析:MADGNet 的“双剑合璧”
MADGNet 的整体架构如图2,主要由两个精密的组件构成:MFMSA 模块和 E-SDM 模块。
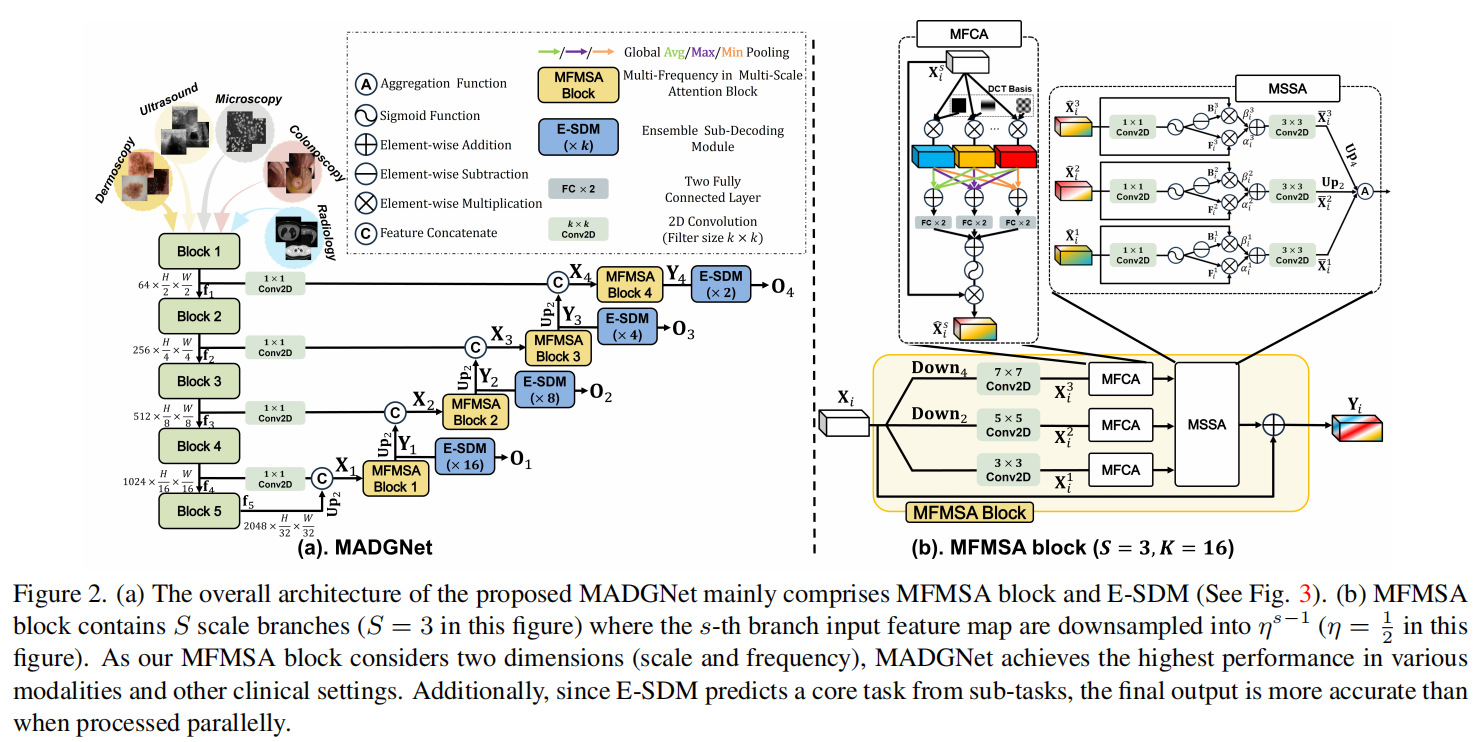
MADGNet 的解码过程依赖于 UpsampleBlock 和其中的 MFMSAttentionBlock。它通过 卷积压缩通道,并利用多尺度采样捕捉不同层级的特征。
3.1 预计算 DCT 基函数
究者通过 2D 离散余弦变换 (DCT) 提取频率统计特性。为了提高效率,代码在初始化阶段会预先计算并注册 DCT 权重(Buffer),而不是在每次前向传播时动态生成。
# 对应论文:3.1 节 Feature Extraction 与 Scale Decomposition
class MFMSAttentionBlock(nn.Module):
def __init__(self, in_channels, scale_branches=2, frequency_branches=16, ...):
super(MFMSAttentionBlock, self).__init__()
self.scale_branches = scale_branches # 尺度分支数 S
# 定义多尺度分支:使用不同扩张率的卷积来获取不同感受野
self.multi_scale_branches = nn.ModuleList([])
for scale_idx in range(scale_branches):
# 这里的计算确保通道数不低于最小阈值 (对应论文 Ce=64 的逻辑)
inter_channel = max(in_channels // 2**scale_idx, self.min_channel) [cite: 546]
self.multi_scale_branches.append(nn.Sequential(
# 使用扩张卷积 (Dilation) 捕捉更广的空间上下文
nn.Conv2d(in_channels, in_channels, kernel_size=3, padding=1 + scale_idx,
dilation=1 + scale_idx, groups=groups, bias=False),
nn.BatchNorm2d(in_channels), nn.ReLU(inplace=True),
# 将通道数压缩至 inter_channel (例如从编码器融合后的 128 压至 64) [cite: 546]
nn.Conv2d(in_channels, inter_channel, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(inter_channel), nn.ReLU(inplace=True)
))
3.2频率处理细节:如何用代码做“频谱分析”
MultiFrequencyChannelAttention (MFCA) 是通过频率域特征校准通道权重的核心。
论文提到医疗图像在不同频率段有不同的表现 。在 mfmsnet.py 中,get_freq_indices 函数硬编码了经过实验筛选的最优频率索引(如 top16),这就像是在收音机里预设了 16 个信号最强的电台频道。模型不需要扫描整个频谱,而是直接监听这 16 个最能代表病灶边界的“特征频道”。
预计算与频率选择 (Top-K)
# 对应论文公式 (3) 的基函数预处理
def get_dct_filter(self, tile_size_x, tile_size_y, mapper_x, mapper_y, in_channels):
# 创建一个全零的 DCT 过滤器张量
dct_filter = torch.zeros(in_channels, tile_size_x, tile_size_y)
for t_x in range(tile_size_x):
for t_y in range(tile_size_y):
# 根据余弦频率索引 (mapper_x, mapper_y) 构建 2D 滤波器
# 这对应了论文中选择最关键的“特征频道”的逻辑
dct_filter[:, t_x, t_y] = self.build_filter(t_x, mapper_x, tile_size_x) *
self.build_filter(t_y, mapper_y, tile_size_y)
return dct_filter
三重全局池化与注意力生成
不同于传统的 SE-Block 只用平均池化,MADGNet 同时使用了平均(Avg)、最大(Max)和最小(Min)池化来捕捉频率分布的极值特性 。,其中 。
# 对应论文公式 (4)
def forward(self, x):
batch_size, C, H, W = x.shape
# ... 省略对齐池化尺寸的代码 ...
multi_spectral_feature_avg, multi_spectral_feature_max, multi_spectral_feature_min = 0, 0, 0
# 遍历所有预设的 DCT 频率分支
for name, params in self.state_dict().items():
if'dct_weight'in name:
# 特征图与 DCT 基函数相乘,提取特定频率分量
x_pooled_spectral = x_pooled * params
# 核心创新:同时使用平均、最大、最小池化捕捉极值
multi_spectral_feature_avg += self.average_channel_pooling(x_pooled_spectral)
multi_spectral_feature_max += self.max_channel_pooling(x_pooled_spectral)
multi_spectral_feature_min += -self.max_channel_pooling(-x_pooled_spectral)
# 通过全连接层 (FC) 聚合各统计量的频率特征
multi_spectral_avg_map = self.fc(multi_spectral_feature_avg / self.num_freq)
multi_spectral_max_map = self.fc(multi_spectral_feature_max / self.num_freq)
multi_spectral_min_map = self.fc(multi_spectral_feature_min / self.num_freq)
# 融合并应用 Sigmoid 激活,生成最终的通道注意力图
multi_spectral_attention_map = F.sigmoid(multi_spectral_avg_map + multi_spectral_max_map + multi_spectral_min_map)
return x * multi_spectral_attention_map.expand_as(x)
3.3 CascadedSubDecoder (集成子解码/E-SDM)
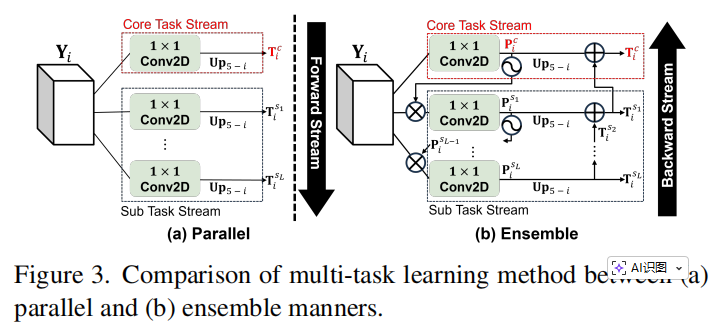
为了解决深监督学习中的信息丢失问题,CascadedSubDecoderBinary 类实现了一种“由难到易”的级联预测机制 。
前向流(Forward Stream): 模型先预测最难的“核心区域”(Map),然后利用这个预测结果作为注意力权重,去指导“距离图”(Distance)和“边界”(Boundary)的生成 。 后向流(Backward Stream): 在计算最终损失前,模型将低分辨率的预测结果通过 Up算子放大,并与高分辨率的子预测进行残差相加(Ensemble) 。这种做法能够显著提升模型对精细结构(如细胞核边缘、细小血管)的刻画能力 。
该模块实现了深监督下的多任务级联,减少大幅度上采样带来的信息丢失。
class CascadedSubDecoderBinary(nn.Module):
def __init__(self, in_channels, num_classes, scale_factor):
super(CascadedSubDecoderBinary, self).__init__()
# 定义区域(Map)、距离图(Distance)和边界(Boundary)三个预测头
self.output_map_conv = nn.Conv2d(in_channels, num_classes, kernel_size=1)
self.output_distance_conv = nn.Conv2d(in_channels, num_classes, kernel_size=1)
self.output_boundary_conv = nn.Conv2d(in_channels, num_classes, kernel_size=1)
self.upsample = nn.Upsample(scale_factor=scale_factor, mode='bilinear', align_corners=True)
def forward(self, x):
# (1) 前向流:依次预测核心区域、距离图和边界
map_p = self.output_map_conv(x)
# 级联指导:区域预测图(Sigmoid后)作为注意力指导距离图预测
distance_p = self.output_distance_conv(x) * torch.sigmoid(map_p)
# 进一步指导:距离图指导边界预测
boundary_p = self.output_boundary_conv(x) * torch.sigmoid(distance_p)
# (2) 后向流:通过上采样和残差融合补偿信息
# 首先上采样最细粒度的边界预测
boundary = self.upsample(boundary_p)
# 级联补偿:将上采样的边界信息反馈给距离图预测
distance = self.upsample(distance_p) + torch.sigmoid(boundary)
# 最终预测:将修复后的距离图信息反馈给核心区域预测
map = self.upsample(map_p) + torch.sigmoid(distance)
return map, distance, boundary
总结实现逻辑
(1) MFMSA 模块利用 ModuleList 并行处理不同尺度,并巧妙地将 DCT 频谱分析 整合进通道注意力中,让模型能够“听懂”图像的频率特性 。
(2) E-SDM 模块摒弃了简单的并行多任务,改用 map -> distance -> boundary 的前向引导和 boundary -> distance -> map 的后向集成,确保上采样后的结果依然保留精细的结构细节 。
4.损失函数与优化
论文在训练时采用了一套组合损失:
包含了加权 IoU 损失、加权交叉熵 (BCE) 损失,以及针对距离图的 MSE 损失 。
使用 cosine annealing 学习率调度器,从 逐渐衰减至 ,确保模型在训练后期能平稳收敛到局部最优解 。
代码中使用了 50% 概率的水平/垂直翻转以及 的随机旋转。这些看似简单的增强,对于维持“模态无关”的泛化性至关重要 。
5.实验结果
研究团队在 6 种模态、15 个数据集上进行了疯狂测试,包括皮肤镜、放射影像、超声、显微镜、结肠镜和眼底图。
(1) 性能霸榜: 在几乎所有测试中,MADGNet 的 Dice 指数(分割准确度)都优于 UNet++、TransUNet 等一众明星模型。
(2) 泛化性极强: 在完全未见过的新医院数据(Unseen settings)上,MADGNet 的领先优势更加明显。
(3) 效率卓越: 模型拥有约 31M 参数,推理速度达 0.024 秒/张,完全能满足临床实时性的要求。
6.批判性分析
虽然 MADGNet 表现惊艳,但可能存在如下问题:
(1) 超参数敏感度: 频率分支数 和尺度分支数 的选择对性能有影响。虽然论文给出了推荐值,但在面对极端罕见的医疗影像时,可能需要更自动化的搜索机制(如 NAS)来确定最佳参数。
(2) 显存占用: 引入多频率分支和多尺度分解虽然提升了精度,但在处理 3D 医疗影像(如 CT 序列)时,由于维度的增加,计算开销和显存占用可能会指数级上升。
(3) 频率选择策略: 目前主要采用 Top-K 频率选择策略。未来是否可以引入“可学习的频率滤波器”,让模型动态地根据当前图像内容自适应地开关特定的频率通道?
不管怎么说,MADGNet 证明了在医疗 AI 中,频率分析不应被遗忘。如果你正在从事医疗影像分割或者跨域学习的研究,这篇论文中关于 DCT 与多尺度结合的思路,非常值得借鉴!
<原文链接:https://mp.weixin.qq.com/s/AeUjWXR2rTMKIrso33zLjw








暂无评论内容