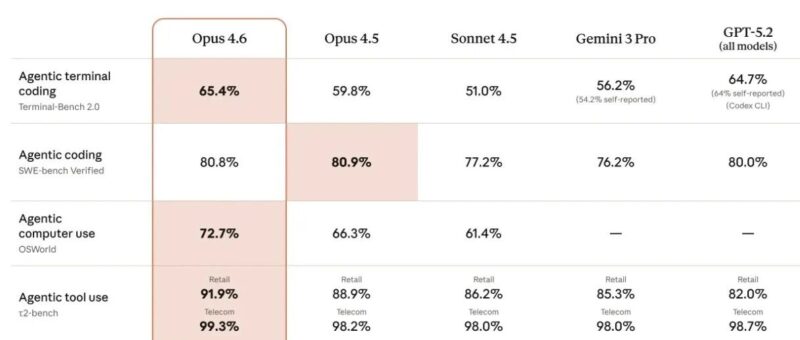



刚刚,Anthropic 发布 Claude Opus 4.6 在知识工作评测 GDPval-AA 上,Opus 4.6 赢 GPT-5.2 约 144 Elo,赢自家前代 Opus 4.5 约 190 Elo 同时拿下 Terminal-Bench 2.0(Agent 编码)、Humanity's Last Exam(多学科推理)、BrowseComp(Agent 搜索)的最高分 这是 Opus 级模型第一次支持 1M token 上下文窗口(beta),输出上限拉到 128K token 模型之外,Anthropic 这次把产品线也一起更新了。Claude Code 加了 agent teams,Excel 升级,PowerPoint 新出了 research preview,API 加了 adaptive thinking 和 context compaction 先看总表 分项来看 知识工作(GDPval-AA) 这个评测由 Artificial Analysis 独立运营,测的是金融、法律等专业领域的实际工作能力。Opus 4.6 在各个子领域都排在前面 Agent 搜索(DeepSearchQA / BrowseComp) BrowseComp 测的是模型在网上找难找的信息的能力。Opus 4.6 单 Agent 跑分就已经领先,加上多 Agent 框架之后分数到了 86.8% Agent 编码(Terminal-Bench 2.0 / SWE-bench Verified) Terminal-Bench 2.0 拿了最高分。SWE-bench Verified 平均跑了 25 轮,调整 prompt 后最高到了 81.42% 多学科推理(Humanity's Last Exam / ARC AGI 2) Humanity's Last Exam 跑的时候带了 web search、code execution、context compaction(50K token 触发,最大 3M token),用了 max effort + adaptive thinking ARC AGI 2 用了 max effort 和 120K thinking budget 1M 上下文不新鲜,但 Opus 级模型一直没给 之前的问题是 context rot,上下文一长,模型表现就往下掉。Opus 4.6 在 MRCR v2 八针 1M 测试里拿了 76%,同一个测试 Sonnet 4.5 只有 18.5% 这特么...足足四倍 Anthropic 说 Opus 4.6 在大量文档中检索信息的能力也有明显提升,能在几十万 token 的上下文里追踪信息,抓住 Opus 4.5 会漏掉的细节 除了上面几个主要方向,Opus 4.6 还跑了软件工程、多语言编码、长期连贯性、网络安全、生命科学几个方向 根因分析(OpenRCA) 测的是模型诊断复杂软件故障的能力。每个 case 如果所有生成的根因要素都和 ground truth 匹配就得 1 分,否则 0 分 多语言编码 长期连贯性(MCP Atlas) Opus 4.6 用 max effort 跑出最高分。用 high effort 的时候也到了 62.7%,同样领先 网络安全(CyberGym) 跑的时候没开 thinking,用默认 effort、temperature 和 top_p,给了一个 think tool 做多轮评测的交叉思考 生命科学 Anthropic 自己用 Claude 造 Claude。工程师每天用 Claude Code 写代码,每个新模型都先在内部跑 他们对 Opus 4.6 的观察:模型会自动把精力集中在任务最难的部分,简单的地方快速通过,处理模糊问题时判断更好,长时间工作保持稳定 但也有个问题,Opus 4.6 有时候会「想太多」。简单任务上会增加成本和延迟,Anthropic 建议这种场景把 effort 从默认的 high 调到 medium Early Access 合作伙伴的反馈集中在三点:能自主工作不需要手把手带,之前模型搞不定的任务能搞定了,改变了团队协作的方式 Claude Code:agent teams 可以同时起多个 Agent,让它们并行工作、自主协调。适合能拆成独立子任务的场景,比如大规模 code review 你可以用 Shift+Up/Down 或者 tmux 随时接管任意一个子 Agent。目前是 research preview Claude in Excel 能处理更长、更复杂的任务了。可以先规划再执行,能自动识别非结构化数据并推断出合理的表结构,支持条件格式和数据验证,多步操作一次完成 Claude in PowerPoint 这个东西目前,research preview 阶段,Max、Team、Enterprise 可用 Claude 会读你的版式、字体、母版,保持品牌一致性。可以从模板出发,也可以从一段描述直接生成整套 deck 一个实用的组合:先用 Claude in Excel 处理和结构化数据,再用 Claude in PowerPoint 做可视化呈现 Cowork 在 Cowork 里,Opus 4.6 可以自主执行多任务。跑分析、做研究、处理文档、表格、演示文稿,都可以自动跑 Adaptive thinking Effort 控制 Context compaction(beta) 1M 上下文(beta) 128K 输出 US-only inference Anthropic 说这是他们做过最全面的安全评估,很多测试是第一次用 自动行为审计里,Opus 4.6 的对齐偏差率(欺骗、谄媚、配合滥用等)和 Opus 4.5 持平。over-refusal 率(该回答却拒绝)是近期 Claude 模型里最低的 新增了用户福祉评测、更复杂的拒绝危险请求测试、模型是否会偷偷执行有害操作的升级版测试 因为 Opus 4.6 的网络安全能力提升明显,Anthropic 额外开发了 6 个新的网络安全探针来追踪潜在滥用。同时也在用这个模型帮开源软件找漏洞和打补丁 一个细节:system card 里提到他们首次用可解释性(interpretability)技术去理解模型行为的底层原因,试图抓住标准测试可能漏掉的问题 详细的能力和安全评估在 system card 里:https://www.anthropic.com/claude-opus-4-6-system-card 今天起在 claude.ai、Claude API、AWS、GCP、Azure 可用 模型 API 标识: 定价:25 每百万 token(200K 以内),37.50 每百万 token(200K 以上)
翻译成人话,就是十局赢七局跑分





长上下文


其他领域的 benchmark





Anthropic 内部怎么用的
产品更新
API 更新
以前 extended thinking 只有开和关两个选项。现在 Claude 可以自己判断什么时候需要深度推理,什么时候快速过。默认 effort 是 high,这个档位下模型会在需要的时候自动启用深度推理
四档可选:low、medium、high(默认)、max。开发者可以根据任务调
长对话或 Agent 任务快撞到上下文窗口的时候,自动把旧的上下文压缩成摘要替换掉,触发阈值可配置
超过 200K token 的输入,价格从 涨到10/百万 token,输出从 涨到37.50。200K 以内价格不变
大输出任务不用拆成多次请求了
需要数据留在美国境内的,可以选 US-only inference,价格 1.1 倍安全

![图片[15]-Claude Opus 4.6 发布,全线碾压 GPT-5.2,一文详解-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/02/20260209004912248-1770569352-4332bd839883f421b8f738e75fce3504.png)
定价
claude-opus-4-6![图片[16]-Claude Opus 4.6 发布,全线碾压 GPT-5.2,一文详解-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/02/20260209004915722-1770569355-e691651ae53c2ae5afcea9172c3d4a79.png)
<原文链接:https://mp.weixin.qq.com/s/L3Tbd4KMmPnahnStnunTVA










暂无评论内容