



今天,我们正式发布并开源GLM-OCR,以“小尺寸、高精度”实现文档解析能力新标杆。作为一款轻量的专业级OCR模型,其核心亮点如下:
- 性能SOTA:以94.6分登顶OmniDocBench V1.5,并在公式识别、表格识别、信息抽取的多项主流基准中均取得SOTA表现;
- 场景优化:专攻真实业务痛点,在手写体、复杂表格、代码文档及印章等高难场景中表现稳健;
- 推理高效:仅0.9B参数规模,支持vLLM、SGLang和Ollama部署,显著降低推理延迟与算力开销,适合高并发与边缘部署;
- 开源易用:同步开源完整SDK与推理工具链,环境依赖简单,支持一行命令快速调用,轻松接入现有业务系统。
性能SOTA、精准干活儿
得益于自研CogViT视觉编码器与深度场景优化,GLM-OCR实现了“小尺寸,高精度”。
GLM-OCR参数量仅0.9B,但在权威文档解析榜单OmniDocBench V1.5中以94.6分取得SOTA性能。在文本、公式、表格识别及信息抽取四大细分领域的表现优于多款OCR专项模型,性能接近Gemini-3-Pro。
![图片[1]-GLM-OCR发布:性能SOTA,搞定复杂文档-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/02/20260205174729322-1770284849-eeecbad0294618940356410150a3383e-scaled.png)
除了公开榜单,我们还针对真实业务中的六大核心场景进行了内部测评。结果显示,GLM-OCR在代码文档、真实场景表格、手写体、多语言、印章识别、票据提取等维度均取得显著优势。
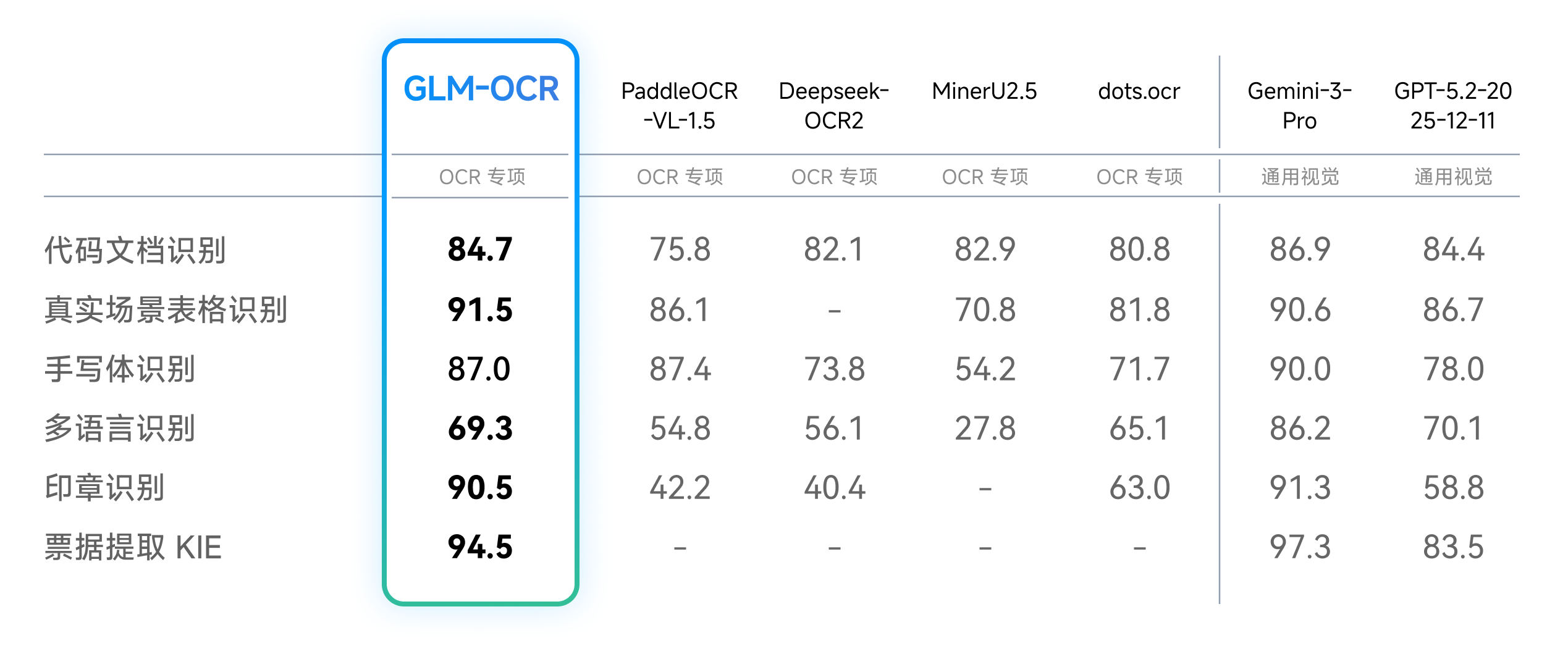
案例实测
在实际应用中,GLM-OCR能够精准解析扫描件、PDF、表格及票据,有效解决手写、印章、竖排及多语言混排难题,在复杂版式下依然保持极高的准确率和鲁棒性。
通用文本识别:GLM-OCR支持照片、截图、扫描件、文档输入,能够识别手写体、印章、代码等特殊文字,可广泛应用于教育、科研、办公等场景。
案例:手写公式识别
![图片[3]-GLM-OCR发布:性能SOTA,搞定复杂文档-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/02/20260205174733775-1770284853-e4c641d9a9e36279190e0523ad25452f.png)
案例:印章识别
![图片[4]-GLM-OCR发布:性能SOTA,搞定复杂文档-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/02/20260205174735868-1770284855-5382ea02a3e28c7b415004e24f31261a.png)
案例:代码识别
![图片[5]-GLM-OCR发布:性能SOTA,搞定复杂文档-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/02/20260205174736672-1770284856-d294038bc86311682707a32be507d54e.jpeg)
复杂表格解析:针对合并单元格、多层表头等复杂结构,模型能精准理解并直接输出HTML代码。无需二次制表,识别结果即可用于网页展示或数据处理,大幅提升表格录入与转换效率。
案例:跨单元格表格
![图片[6]-GLM-OCR发布:性能SOTA,搞定复杂文档-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/02/20260205174737311-1770284857-8dc9d15d54ddafeba38b1a28fe7d40a0.png)
案例:分段表
![图片[7]-GLM-OCR发布:性能SOTA,搞定复杂文档-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/02/20260205174738455-1770284858-95555d6a9cd9dd020578a9bea8960433.png)
信息结构化提取:GLM-OCR可从各类卡证、票据、表格中智能提取关键字段,并输出标准的JSON格式,无缝对接银行、保险及物流等行业系统。
输入图片:
![图片[8]-GLM-OCR发布:性能SOTA,搞定复杂文档-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/02/20260205174740610-1770284860-ce9ac6bc295d093ffa8ea0cc1d009dec.png)
prompt:
请按下列JSON格式输出图中信息:```json{"标题": "中华人民共和国海关出口货物报关单","境内发货人": {"名称":"","统一社会信用代码":"","10位海关代码":""},"出境关别": "","出口日期": "","申报日期": "","备案号": "","境外收货人": "","运输方式": "","运输工具名称及航次号": "","提运单号": "","生产销售单位": {"名称":"","统一社会信用代码":"","10位海关代码":""},"监管方式": "","征免性质": "","许可证号": "","合同协议号": "","贸易国(地区)": "","运抵国(地区)": "","指运港": "","离境口岸": "","包装种类": "","件数": "","毛重(千克)": "","净重(千克)": "","成交方式": "","运费": "","保费": "","杂费": "","商品信息": [{"项号": 1,"商品编号": "","商品名称": "","数量": "","单价": "","总价": "","币制": "","原产国(地区)": "","最终目的国(地区)": "","境内货源地": "","征免": "","规格型号(申报要素)": ""}, // 如果有多种商品,新建一个字典继续在列表中记录]}```
输出:
```json{"标题": "中华人民共和国海关出口货物报关单","境内发货人": {"名称": "建德市佳泓工具有限公司","统一社会信用代码": "913301827042918701","10位海关代码": ""},"出境关别": "","出口日期": "","申报日期": "","备案号": "","境外收货人": "ROSS PROCUREMENT, INC.","运输方式": "水路运输","运输工具名称及航次号": "","提运单号": "","生产销售单位": {"名称": "建德市佳泓工具有限公司","统一社会信用代码": "913301827042918701","10位海关代码": ""},"监管方式": "一般贸易","征免性质": "一般征税","许可证号": "","合同协议号": "70037636","贸易国(地区)": "美国","运抵国(地区)": "美国","指运港": "美国","离境口岸": "北三集司","包装种类": "纸箱+双泡壳+标贴","件数": "300","毛重(千克)": "2700.00","净重(千克)": "2499.00","成交方式": "FOB","运费": "","保费": "","杂费": "","商品信息": [{"项号": 1,"商品编号": "8205400000(999)","商品名称": "螺丝刀","数量": "1200套","单价": "","总价": "7896.00","币制": "USD","原产国(地区)": "中国","最终目的国(地区)": "美国","境内货源地": "杭州其他","征免": "照章征税","规格型号(申报要素)": ""}]}```
批量处理与RAG支持:GLM-OCR支持大批量文档的识别与解析,其高精度的识别能力和规整的输出格式,可为检索增强生成(RAG)提供坚实基础。
更快、更便宜
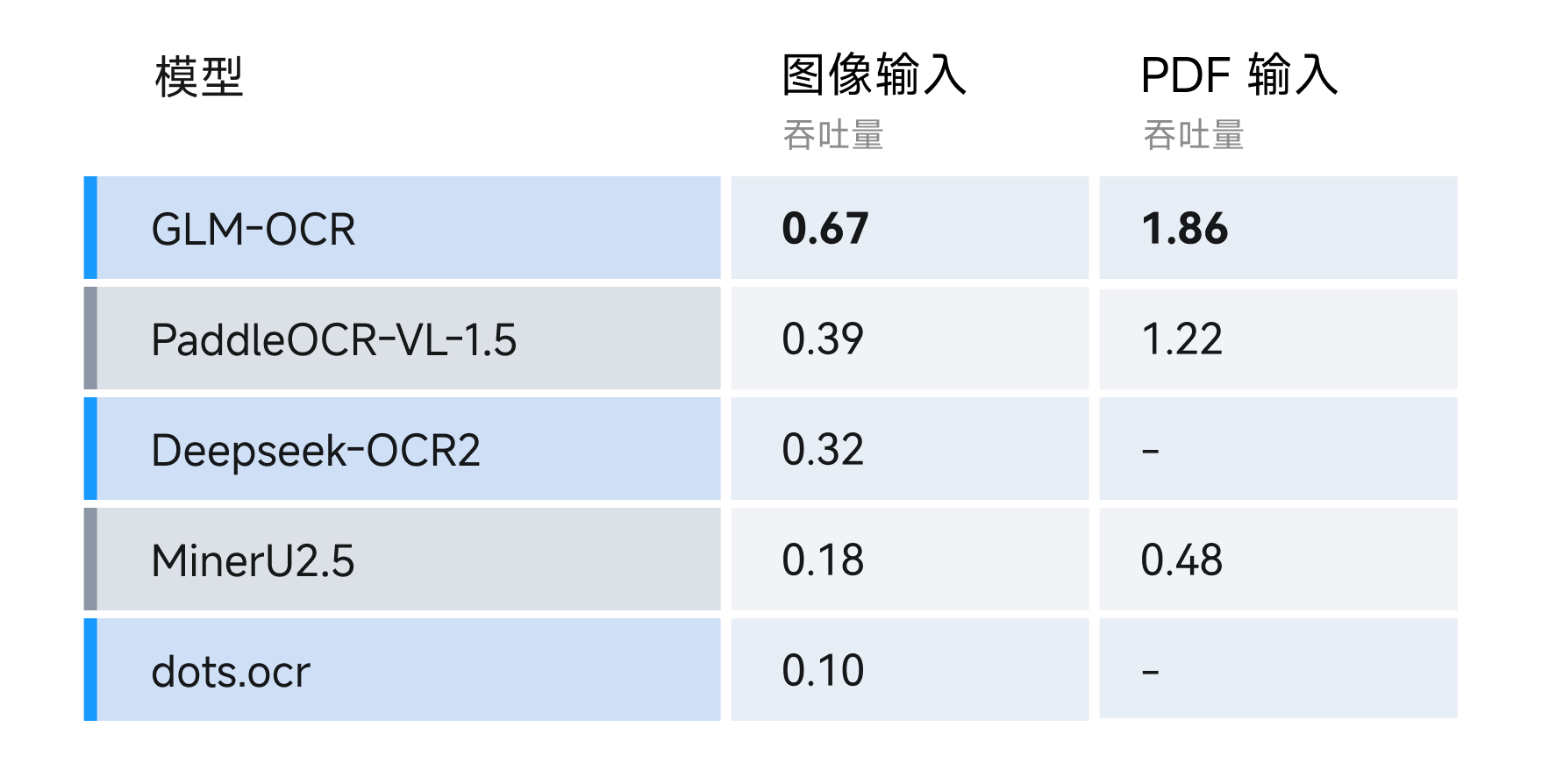
速度方面,我们对比了在相同硬件环境与测试条件下(单副本,单并发),分别以图像文件和PDF文件为输入,不同OCR方法完成解析并导出Markdown文件的速度差异。结果显示,GLM-OCR处理PDF文档的吞吐量达1.86页/秒,图片达0.67张/秒,速度显著优于同类模型。
价格方面,API输入输出同价,仅需0.2元/百万Tokens。1元即可处理约2000张A4大小扫描图片或200份10页简单排版PDF,成本约为传统OCR方案的1/10。
技术细节
在训练策略方面,GLM-OCR率先将多Tokens预测损失(MTP)引入OCR模型训练过程,以增强损失信号密度并提升模型学习效率。并且,通过持续且稳定的全任务强化学习训练,能够显著提升模型在复杂文档场景下的整体识别精度与泛化能力。
上述性能提升还得益于GLM-OCR在多模态模型结构上的系统性设计。模型整体采用“编码器-解码器”架构,继承自GLM-V系列,由视觉编码器(ViT)、跨模态连接层和语言解码器三大核心模块组成。其中,视觉侧集成了自研的CogViT视觉编码器(400M参数),并在数十亿级图文对数据上引入CLIP策略进行大规模预训练,使模型具备了强大的文字与版面语义理解能力。
为实现视觉与语言信息的高效融合,GLM-OCR设计了一套轻量而高效的连接层结构,融合SwiGLU机制并引入4倍下采样策略,能够精准筛选并保留关键视觉 Token,将高密度语义信息高效传递至后端的GLM-0.5B解码器,从而支撑高精度的OCR识别输出。
在整体系统层面,GLM-OCR采用“版面分析→并行识别”的两阶段技术范式。其中,版面分析模块基于PP-DocLayout-V3实现,能够在版式多样、结构复杂的文档场景下实现稳定、高质量且高效率的OCR解析效果。
开源与在线体验
1.开源地址
Github:https://github.com/zai-org/GLM-OCR - Hugging Face:https://huggingface.co/zai-org/GLM-OCR
2.模型API
- 智谱开放平台:https://docs.bigmodel.cn/cn/guide/models/vlm/glm-ocr
特惠尝鲜礼包上线,2.9元享5000万Tokens:https://bigmodel.cn/special_area - Z.ai:https://docs.z.ai/guides/vlm/glm-ocr
3.在线体验
- Z.ai:https://ocr.z.ai
未来,我们将持续迭代GLM-OCR,推出更多尺寸版本,并将能力延伸至更多语言和视频OCR,全面拓宽视觉智能的应用边界。
![图片[10]-GLM-OCR发布:性能SOTA,搞定复杂文档-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/12/20251209144409538-1765262649-aaa5efb038e410b56d796120a4a6466d.png)
<原文链接:https://mp.weixin.qq.com/s/TVanw2YyfxMlzoaOrR-Naw













暂无评论内容