


![图片[1]-AI测试新范式:用智能体测试智能体的终极指南-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/01/20260127175923494-1769507963-6523c55e73eea25e073a0cd1ff14f7b7.png)
如何使用智能体测试智能体
传统测试依赖于固定的输入和精确的输出。但智能体使用语言进行交流,因此不存在单一的“正确”响应。
这就是为什么我们通过模拟用户和评判者,使用其他智能体来测试智能体。你看,用智能体制定的规则,来考核智能体本身。
智能体(Agent)在人工智能领域中指能够感知环境、做出决策并执行动作的自主系统。在对话系统中,智能体通常指能够理解和生成自然语言的模型或程序。
今天,让我们通过构建一个使用场景来测试智能体与其他智能体的流水线,来理解智能体测试。
我们的开源技术栈:
CrewAI 用于智能体编排。 LangWatch Scenario 用于构建评估流水线。 PyTest 作为测试运行器。
以下是流程示意图:
![图片[2]-AI测试新范式:用智能体测试智能体的终极指南-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/01/20260127175924815-1769507964-6873d803fa77eec5a02295b959bf15dd.gif)
定义三个智能体: 你要测试的智能体。 一个模拟真实用户的用户模拟智能体。 用于评估的评判智能体。
让你的智能体和用户模拟智能体彼此交互。 基于指定的标准,使用评判智能体评估这次交换。
接下来,让我们实现它!
定义规划者团队
为了这个演示,我们将使用CrewAI来构建一个旅行规划智能体。它将接收用户查询,并回应旅行建议、简要行程和估算预算。
CrewAI 是一个开源的框架,专门用于设计和编排多个AI智能体协作完成任务,类似一个团队。在这个上下文中,它帮助构建和管理智能体之间的交互。
![图片[3]-AI测试新范式:用智能体测试智能体的终极指南-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/01/20260127175926497-1769507966-f4b0c28b0e24b7e37333740266e6bc92.png)
配置Crew进行测试
在场景库中,您的Agent类应该:
注:在智能体系统中,“Crew”通常指一个由多个Agent组成的团队,协同完成任务;“Agent class”指在编程中定义Agent行为的类;“Scenario library”是用于测试智能体的场景集合。
![图片[4]-AI测试新范式:用智能体测试智能体的终极指南-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/01/20260127175926822-1769507966-e2cb7308a088d99535359bab5ce94cff.png)
继承自 AgentAdapter 类。 定义一个 call()方法,该方法接收输入并返回输出。
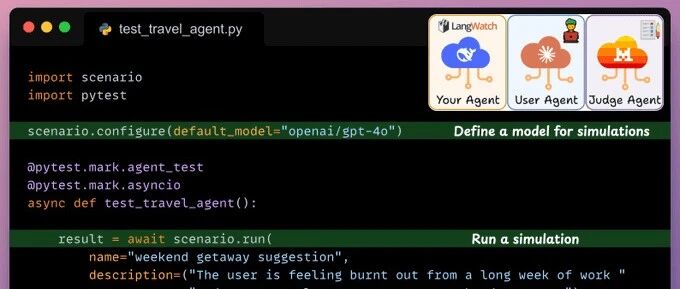
定义测试
最后,在我们的测试中,我们使用 scenario.run 方法模拟旅行代理与用户模拟代理之间的对话。
交换之后,Judge Agent 根据指定标准进行评估。LangWatch Scenario 协调一切!
AgentAdapter 类是一个基类,用于标准化智能体的行为接口,便于在复杂系统中集成和复用。
call()方法是智能体处理任务的核心函数,类似于编程中的主函数,负责接收外部输入并生成相应输出。scenario.run 方法用于执行预定义的测试场景,模拟智能体之间的交互过程,以验证其行为。Judge Agent 是一个评估智能体,根据预设的评判标准(如准确性、效率)来打分或提供反馈。LangWatch Scenario 是一个协调框架,用于管理和自动化多个智能体的测试流程,确保测试有序进行。
![图片[5]-AI测试新范式:用智能体测试智能体的终极指南-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/01/20260127175927953-1769507967-ce99f20fcf8a1432cbc41e49267b8a3d.png)
我们指定测试的名称( name参数)。我们指定测试的描述( description参数)。我们指定涉及的代理: 旅行代理:我们要测试的代理。 用户模拟代理:模拟真实用户的代理。 评判代理:根据自然语言指定的标准来评估对话的代理。
最后,我们通过以下命令运行它:uv run pytest -s test_travel_agent.py
代理在人工智能中指的是能够自主执行任务(如对话或决策)的智能体,通常基于大语言模型构建。pytest 是 Python 的一个常用测试框架,用于自动化运行和验证代码,支持命令行操作。
![图片[6]-AI测试新范式:用智能体测试智能体的终极指南-AI Express News](https://www.aiexpress.news/wp-content/uploads/2026/01/20260127175928402-1769507968-fcfb765f813d767efc0b1c4879c5434b.jpeg)
如上所述,评判代理判定这次运行为失败,因为它无法确定地点是否距离<4小时,但这在我们声明评判代理时的标准中已指定。
测试揭示了一个漏洞,我们可以通过提示代理在用户未指定地点时主动询问来修复它。
这就是你如何构建智能体测试管道的方式。
LangWatch Scenario 开源框架协调了这一过程。它是一个基于模拟的、库无关的智能体测试框架。
关键特性:
通过模拟用户在不同场景和边缘情况下的行为来测试代理。 使用强大的多轮控制在对话的任何点进行评估。 通过仅实现一个 call()方法即可集成任何代理。与任何大语言模型评估框架或自定义评估相结合。
大语言模型(LLM)是能够理解和生成人类语言的人工智能模型,评估框架用于测试这些模型的性能。
我的理念是:让天下没有难做的智能体。如果您的企业需要智能体降本提效创收,欢迎后台联系我! 🔥【AI与代码前沿基地】🚀 高频更新!助你抢占技术先机! 🌟 你是否: ❌ 苦恼AI技术更新太快,跟不上核心概念? ❌ 代码实操一学就会,一写就废? ❌ 想获取行业前瞻洞察,却找不到深度解析? ✅ 在这里,你将获得: ▷ 系统性AI知识库:机器学习→深度学习→大模型,零基础到进阶 ▷ 最新技术速递:紧跟ChatGPT、Deepseek等全球AI突破,附实战代码 ▷ 开发者工具箱:Python案例拆解+自动化实操,拒绝纸上谈兵 ▷ AI解决方案:面向您的场景,端到端搭建AI解决方案 📌 点击右上角“关注”✅小木块lambda,快人一步掌握未来! #人工智能 #编程实战 #科技趋势 #干货分享
更多知识学习,尽在 https://www.dailydoseofds.com/
<原文链接:https://mp.weixin.qq.com/s/mg8Iz84CA8hncVBsBoRJ6A








暂无评论内容