


在“预训练(Pre-training)”赋予了大模型广博的知识之后,“后训练(Post-training)”则是决定模型能否在特定任务上表现卓越的关键阶段。面对 SFT(监督微调)、RFT(强化微调/拒绝采样) 和 RLHF(基于人类反馈的强化学习) 这三条路径,技术决策者往往面临艰难的取舍。
![图片[1]-大模型微调的战略抉择!何时该用 SFT?何处需要 RLHF?-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/12/20251211002959682-1765384199-ab11fb7a6d95bdf54697fc87a4a90d6c.png)
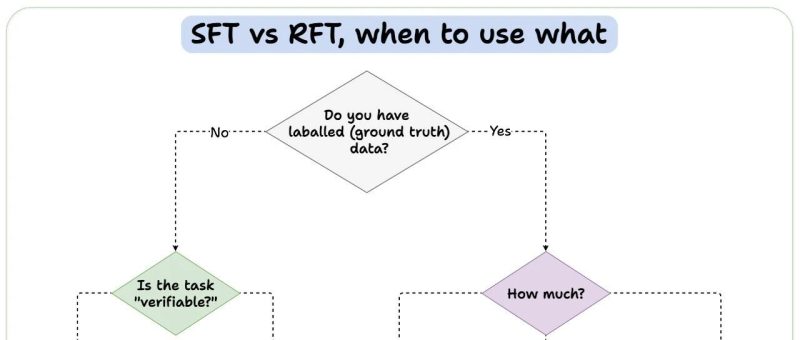
这个流程图不仅仅是一个简单的分类树,它实际上揭示了大模型能力的三个核心维度:数据依赖性、任务可验证性与推理复杂性。
SFT(监督微调)
SFT (Supervised Fine-Tuning) 是目前最成熟、最通用的微调范式。从流程图的右侧分支可以看出,数据量是决定 SFT 权重的核心指标。
核心逻辑
SFT 的本质是利用高质量的 <Prompt, Response> 数据对,通过最大化似然估计(MLE)来调整模型参数。它教会模型的是“指令遵循”的能力和特定领域的“表达规范”。
适用场景
大数据量场景:
策略: 当你拥有超过 10 万条高质量标注数据时,SFT 是绝对的王者。 原理: 在这个量级下,模型能够充分拟合数据的分布,甚至涌现出泛化能力。例如,构建一个垂直领域的医疗问答模型或法律文书生成模型,海量的 SFT 数据能让模型迅速掌握专业术语和逻辑范式。
小数据量且无推理需求:
策略: 流程图右下角指出,如果数据很少且不需要复杂推理(Does COT/reasoning help? -> No),依然选择 SFT。 原理: 这对应于少样本学习(Few-shot Learning)或轻量级微调。对于简单的分类任务、实体抽取或固定格式转换,模型不需要深层的逻辑链条,仅需少量样本即可完成“对齐”。
RFT(强化微调)
RFT (Reinforced Fine-Tuning),在工业界常通过 拒绝采样微调 (Rejection Sampling Fine-Tuning) 来实现,是近年来提升模型数理逻辑能力的关键技术。
核心逻辑
RFT 解决的是“由果导因”的问题。流程图中指出了 RFT 的两个关键触发条件:
任务可验证 (Is the task verifiable? -> Yes) 数据稀缺但需要思维链 (Data < 100 & CoT helps -> Yes)
“可验证性”是 RFT 的灵魂
RFT 的核心在于利用验证器(Verifier)来筛选数据。什么是可验证任务? 指的是那些答案客观唯一或可以通过代码/规则自动判定对错的任务。
数学题: 答案是具体的数值,可以通过计算器验证。 代码生成: 生成的代码可以通过单元测试(Unit Test)来验证。 逻辑谜题: 必须满足特定的约束条件。
RFT 的执行机制
当我们在这些领域缺乏标注数据时,RFT 提供了一种“无中生有”的方案:
探索(Exploration): 让模型针对同一个问题生成 个不同的回答(推理路径)。 验证(Verification): 使用外部工具(如 Python 解释器或数学求解器)判断哪些回答导向了正确结果。 筛选与训练(Selection & Training): 保留那些推理过程正确的样本,将其转化为新的 SFT 数据集回填给模型。
战略价值: RFT 是目前提升模型 Reasoning(推理)能力(如 OpenAI o1 系列技术路线)的核心手段。它通过大量的试错,让模型学会了“如何思考”而非仅仅“背诵答案”。
RLHF(基于人类反馈的强化学习)
RLHF (Reinforcement Learning from Human Feedback) 是流程图中最左侧的分支,它处理的是最复杂、最模糊的领域。
核心逻辑:解决“不可微”的偏好问题
当任务既没有标准答案(No Ground Truth),结果也无法通过代码验证(Not Verifiable)时,RLHF 是唯一的选择。
场景特征: 创意写作、伦理道德判断、情感陪伴、政治敏感性话题。 难点: 无论是写一首诗,还是安抚一个愤怒的用户,都没有绝对的“对”与“错”,只有“好”与“更好”。计算机无法通过简单的 Loss 函数来优化这些指标。
RLHF 的三步走战略
由于缺乏客观真理,我们引入“人类”作为评价函数:
偏好收集: 人类标注员对模型生成的多个回答进行排序(Ranking),而非直接重写。 奖励模型(Reward Model): 训练一个神经网络来模拟人类的评分标准。 强化学习(PPO/DPO): 使用这个 Reward Model 作为裁判,指导主模型在生成过程中不断向“高分区域”靠拢。
战略价值: RLHF 的主要作用不是注入知识,而是对齐(Alignment)。它确保模型是有用的(Helpful)、诚实的(Honest)且无害的(Harmless)。
基于这张流程图和上述分析,我们可以总结出一套针对企业与开发者的决策框架:
| SFT (监督微调) | RFT (强化/拒绝采样) | RLHF (人类反馈强化) | |
|---|---|---|---|
| 数据特征 | |||
| 核心能力 | |||
| 验证方式 | |||
| 典型应用 |
在实际工程落地中,这三者往往不是互斥的,而是递进的:
先做 SFT:无论什么任务,高质量的 SFT 都是冷启动的基础,它决定了模型的下限。 理科用 RFT:涉及逻辑和代码,利用 RFT 制造合成数据,突破数据瓶颈,提升上限。 文科/安全用 RLHF:在 SFT 模型具备基本能力后,用 RLHF 进行最后的打磨,确保模型不仅“懂”,而且“懂事”。
<










暂无评论内容