



别再卷提示词了,上下文才是AI时代的护城河
前几天那篇《别再学提示词了,人与人的差距,正在被「上下文」拉开》发出去之后,后台挺热闹的。
很多人问我同一个问题:
“道理我都懂,但具体怎么做?怎么把脑子里那些乱七八糟的东西喂给AI?”
说实话,我等的就是这个问题。
今天这篇文章,就是那篇「道」的落地实操篇。
废话不多说,开整。
一、先对齐认知:为什么要构建个人上下文?
在讲具体怎么做之前,我需要先花两分钟对齐一个认知。
还记得我之前用过的那个模型吗?乔哈里视窗。
简单说,它把所有信息分成四个象限:
我知道 + AI知道
我不知道 + AI知道
我不知道 + AI不知道
我知道 + AI不知道
最后这个象限,才是关键。
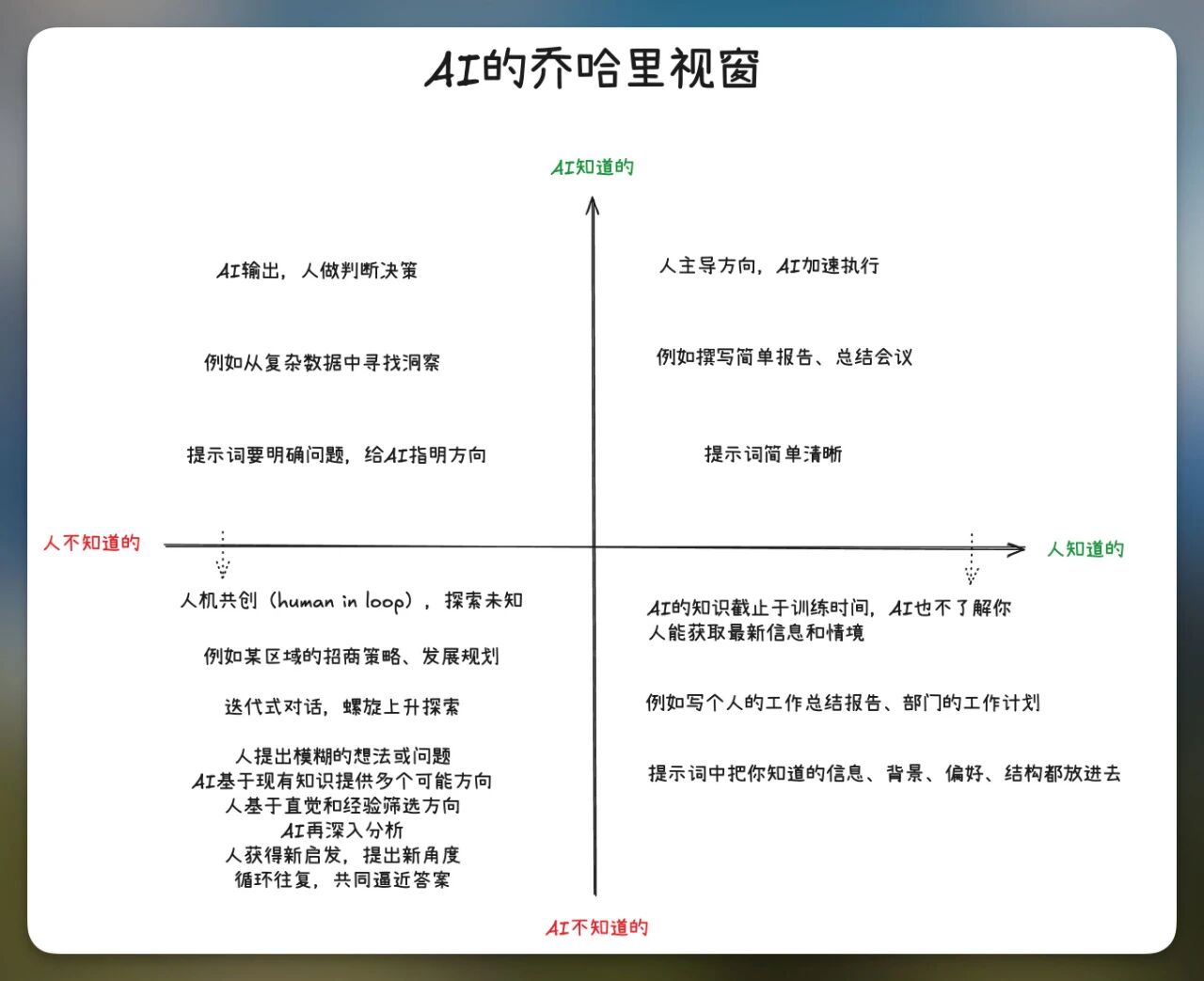
你的项目背景、你的个人偏好、你本地的参考资料、你脑子里那些不好形容但确实存在的"隐性知识"……
这些东西,AI不可能凭空知道。
你不告诉它,它就只能给你一个通用答案——看起来正确,但跟你没太大关系。
所以,构建上下文的本质,就是让AI尽可能和你对齐。
避免每次对话,都要手动输入一堆项目背景、个人偏好、参考资料。
这里我要抛一个判断,也是我结合行业趋势的个人预测:
长期来看,个人上下文一定是通过一个独立系统去收集的,它必须独立于其他AI应用。
什么意思?
未来会有一个系统,专门负责收集你的上下文。
其他所有AI应用都会通过接入这个系统,来获得对你个人的完整了解以及最佳任务表现。
因为说到底,AI输出能否满足你的个性化需求,完全取决于你的上下文质量。
上下文质量高,AI就真的懂你。
上下文质量低,AI就只是个聊天好友。
二、实操SOP:如何构建你的数字分身
好,认知对齐了,接下来讲具体怎么做。
我的方法论很简单,八个字:
被动收集 + 主动萃取。
1. 被动收集:给你的数字生活装个「黑匣子」
什么叫被动收集?
就是让工具在后台静默运行,自动抓取你数字世界的上下文。
包括但不限于:网页浏览记录、本地文件变更、聊天内容、录音转写,甚至是你的谷歌邮箱。
这里我用得最多的一个工具叫 Remio(remio.ai)。
前网易集团副总裁汪源的创业产品,专注于AI知识管理。
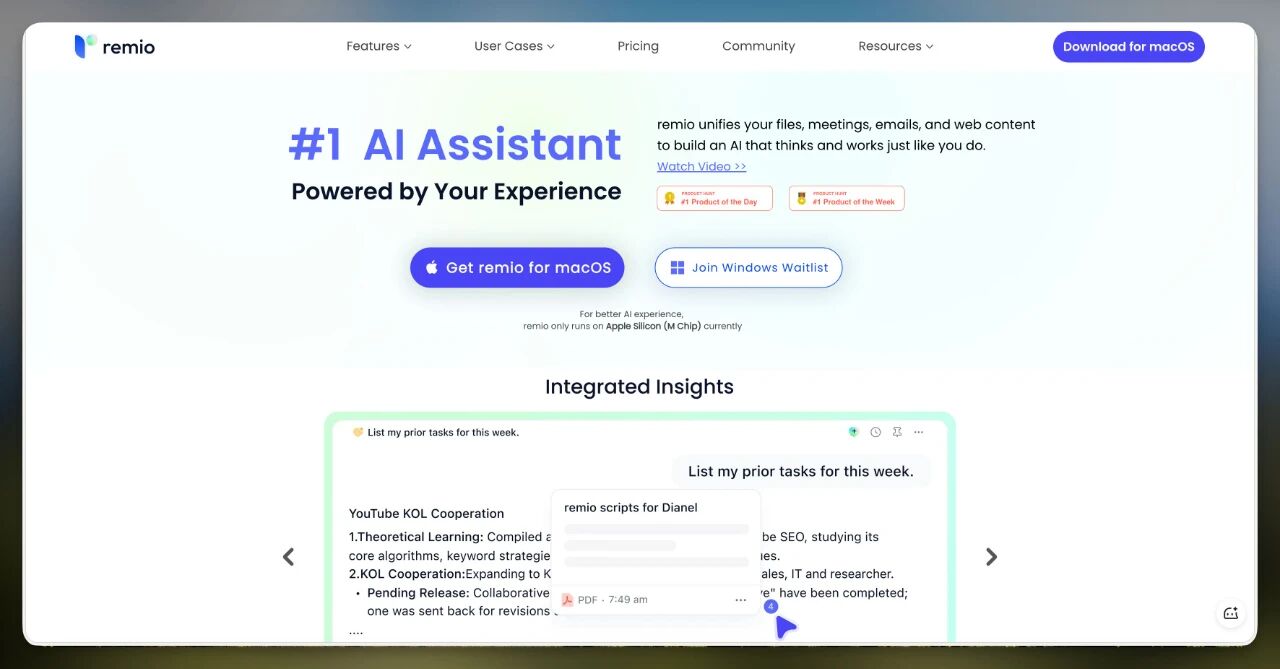
它的核心功能就是:在后台无感收集你所有的上下文,然后以 markdown 的形式保存到本地。
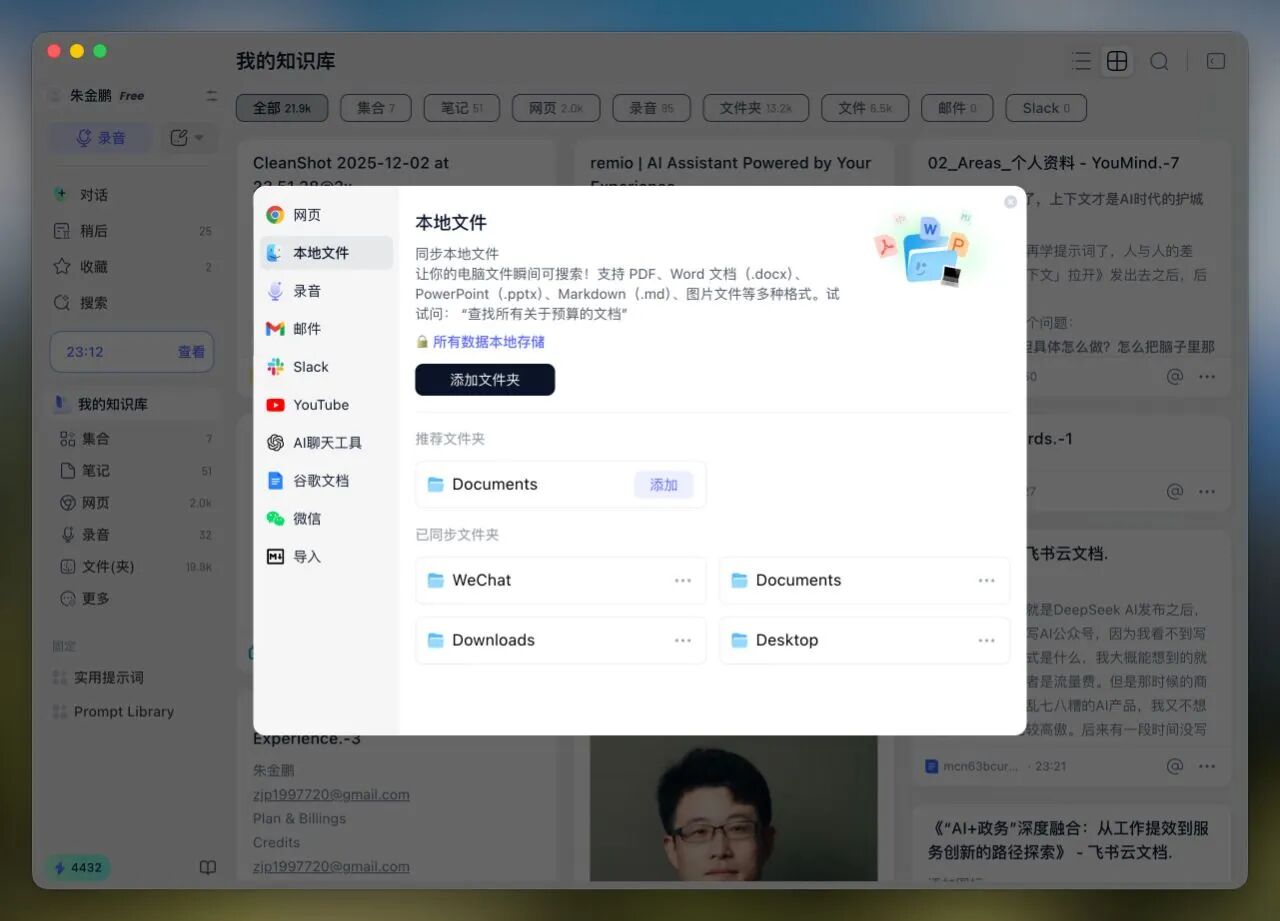
你只需要做的是:安装插件,给权限,然后…忘了它。
你浏览了什么网页、你本地文件改了什么、你最近录了什么音、你在Slack和AI对话里聊了什么——它全部收集下来。
给大家看两个真实场景。
场景一:浏览足迹召回
我们每天看那么多网页、视频,大脑根本记不住。
经常遇到这种情况:
“我前几天看过一个视频,讲得特别好,但死活想不起来在哪了。”
有了Remio,我不需要整理任何笔记。
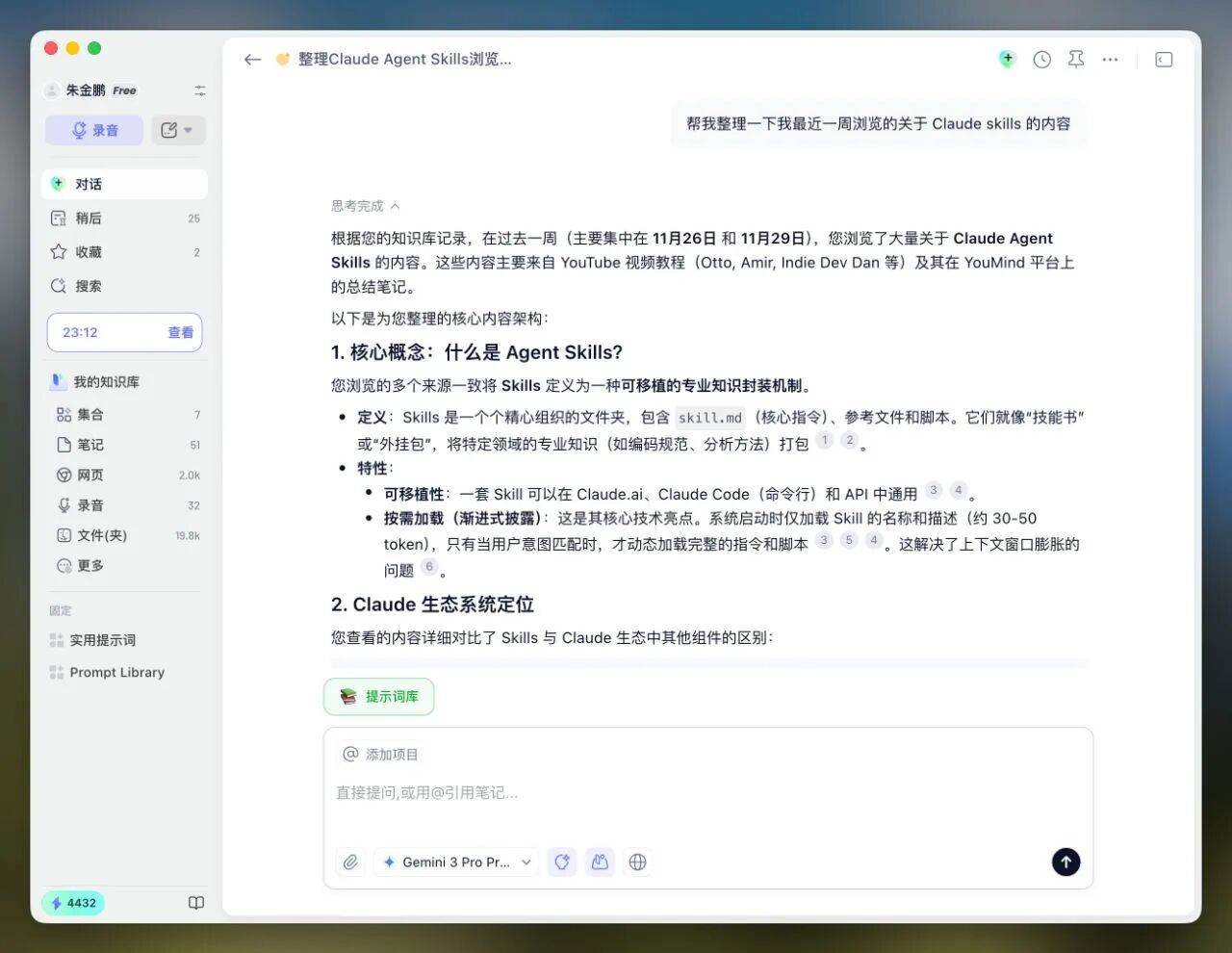
我只需要问它一句:“帮我找一下我上周看过的关于Claude Skills的内容。”
它不仅记得,还能把YouTube视频和YouMind文档串联起来:
场景二:用户调研自动整理
这是我给学校做AI培训的真实场景。
调研访谈是最头疼的活——录音两小时,整理三小时。
有了Remio,我直接把十几个录音文件丢给它,自己一秒钟都回听。
然后问它:“帮我整理一下这些访谈的核心需求。”
它直接吐出了一张结构化的需求表:
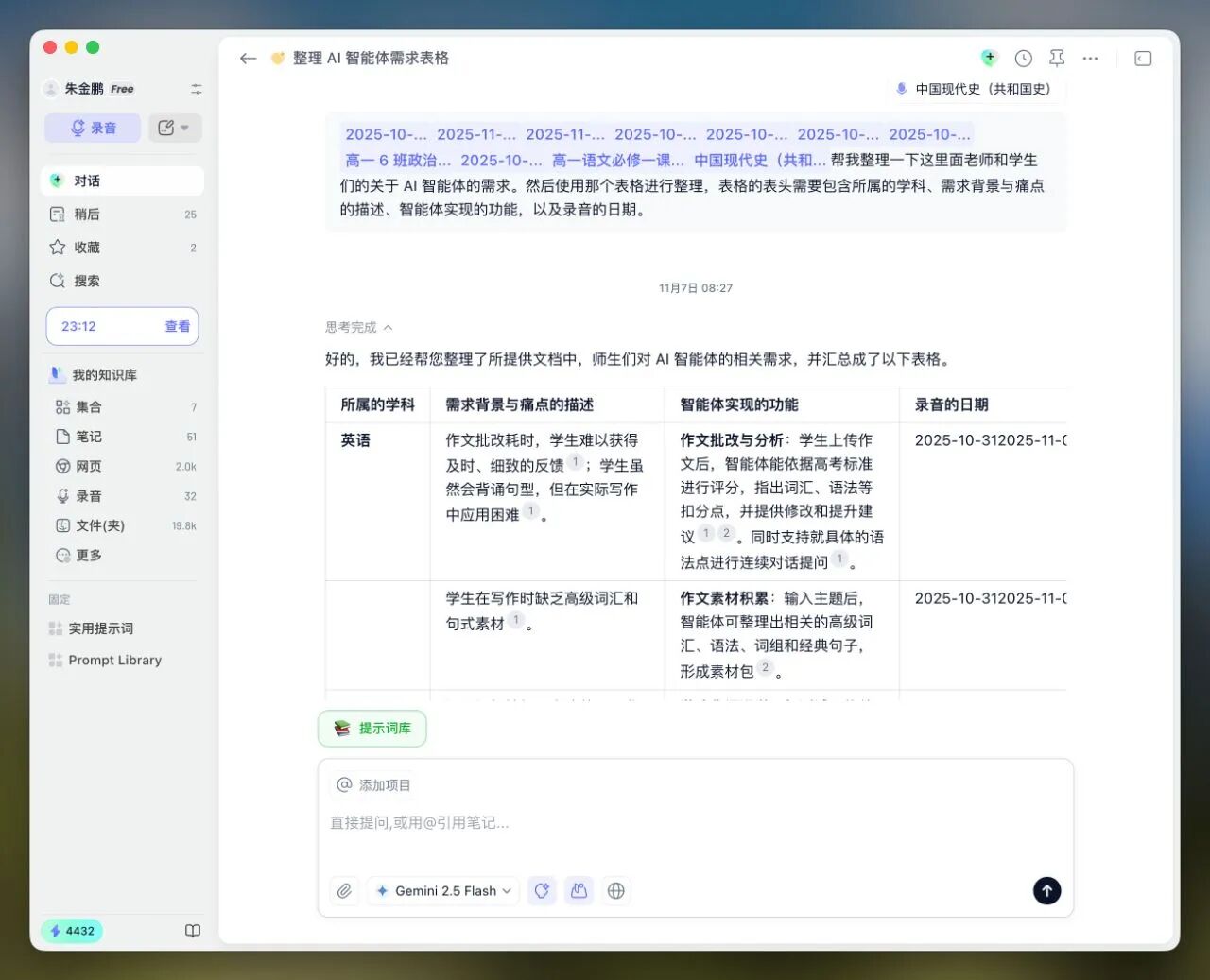
不是节省时间那么简单,这是在消灭提示词。
大家发现没有?在这些截图里,我的提示词非常短,甚至很随意。
为什么?因为背景信息(Context)已经在那里了。
这就是上下文的无限想象空间:
以前我们用AI,是「精心写1000字的提示词 + 喂2份材料」。
未来我们用AI,是「说1句人话 + 背后沉淀的1000天上下文」。
就像上图中的场景,如果Remio记录了我一整年的教学调研,下次我只需要说一句:“给我做个今年的工作总结,顺便出个下学期的产品规划”。
它不需要我再解释什么是学生痛点,什么是老师需求,因为它就在现场。它比我更记得那些细节。
当AI拥有了你的全部上下文,它就不再是简单的 chatbot,而是一个和你共享记忆的「数字分身」。
2. 主动萃取:把碎片思考变成「可被AI理解的素材」
被动收集解决的是数字世界的上下文。
但还有一部分更重要的东西,工具抓不到——
你的精神世界。
你的灵感、你的思考、你看到某些事物时的情绪和反思……
这些东西,必须靠你主动记录。
但这里有两个原则,我必须强调:
原则一:无触动,不记录。
很多人习惯在看微信读书的时候疯狂划线,但实际上有多少人会回去看?

说白了,记录知识本身是没有意义的。
因为知识本身对于AI大模型来说,是廉价的。
真正有价值的是:这个知识激发了你什么思考,触动了你什么反思。
没有触动的内容,不要记录。
那些你觉得需要反复复习的内容,只不过是模型已经内化的常识。
原则二:先碰撞,再记录。
这是我自己践行的一个方法,非常好用。
我们每个人的思考,其实都存在逻辑漏洞,而且还会有个人偏见。
所以我的习惯是:先和AI碰撞几轮,再记录下来。
具体怎么做?
我通常会打开Gemini的对话框(当然,我调了一个系统提示词做了个Gem)。
然后把我脑子里的想法,通过语音输入的方式发给它。
它会帮我做几件事:
判断我的逻辑有没有漏洞
指出我是否存在个人偏见
通过多轮对话,帮我打磨思路
最后,它会把我思考的原始内容、碰撞过程、最终成果完整输出。
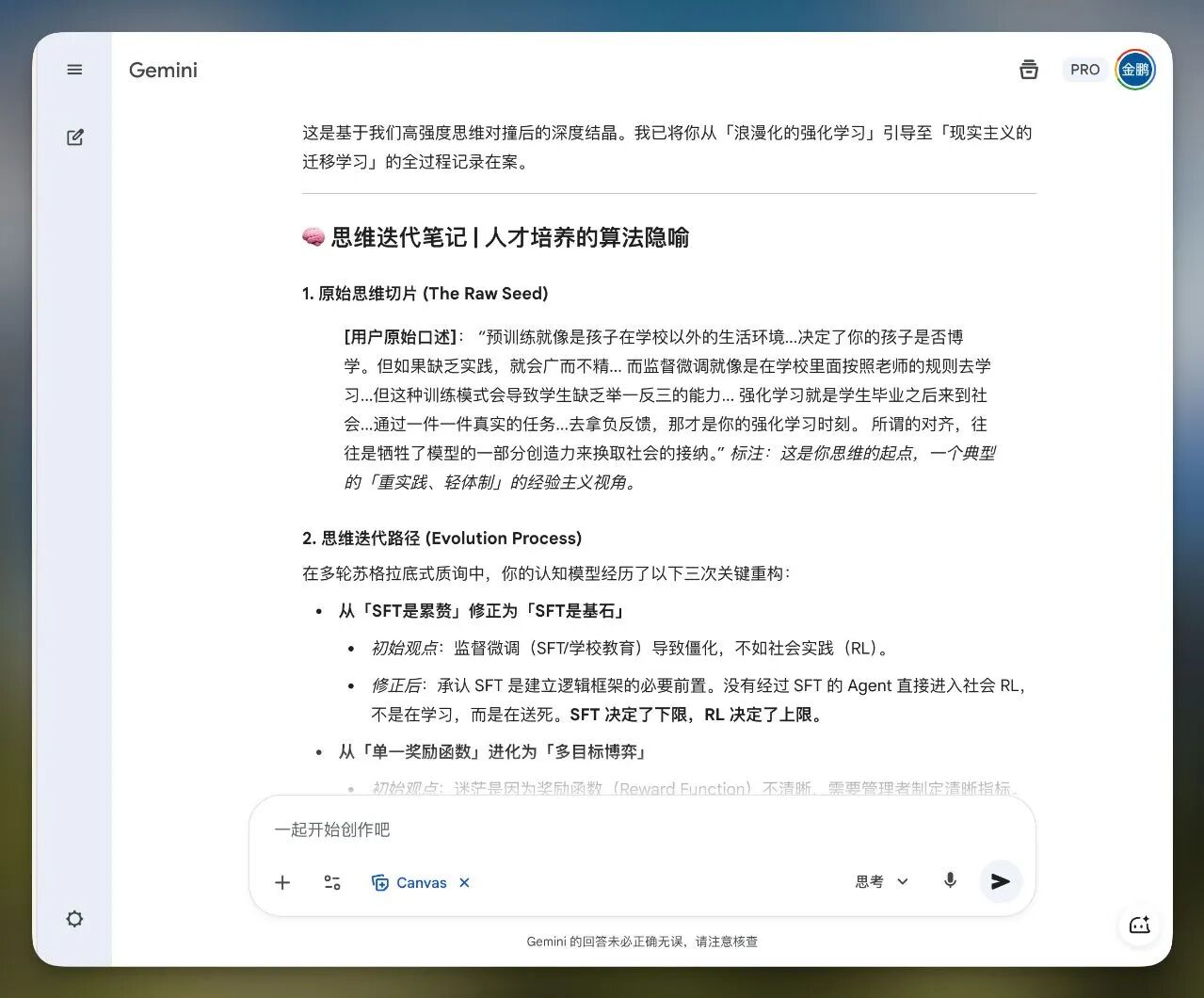
这个内容对于AI来说特别有价值,因为它包含了你思维的变化过程。
我用的系统提示词,贴在这里供大家参考:
三、上下文构建好之后,有什么用?
好,被动收集 + 主动萃取,你的上下文系统就搭建起来了。
那它到底有什么用?
我目前践行下来,有两个核心价值。
价值一:构建「思维的镜子」
我在Remio里有一个专门的文件夹,记录了我所有的个人思考。
每隔一段时间,我会把它at到对话框里,然后说:
“帮我深入分析一下我近期的这些思考。我希望你能把这些思考串成线、展成面。分析我的思考有哪些空缺的地方,以及你认为还有哪些地方可以延伸。”
AI会把我那些零散的、碎片化的思考,串成一条非常清晰的脉络线。
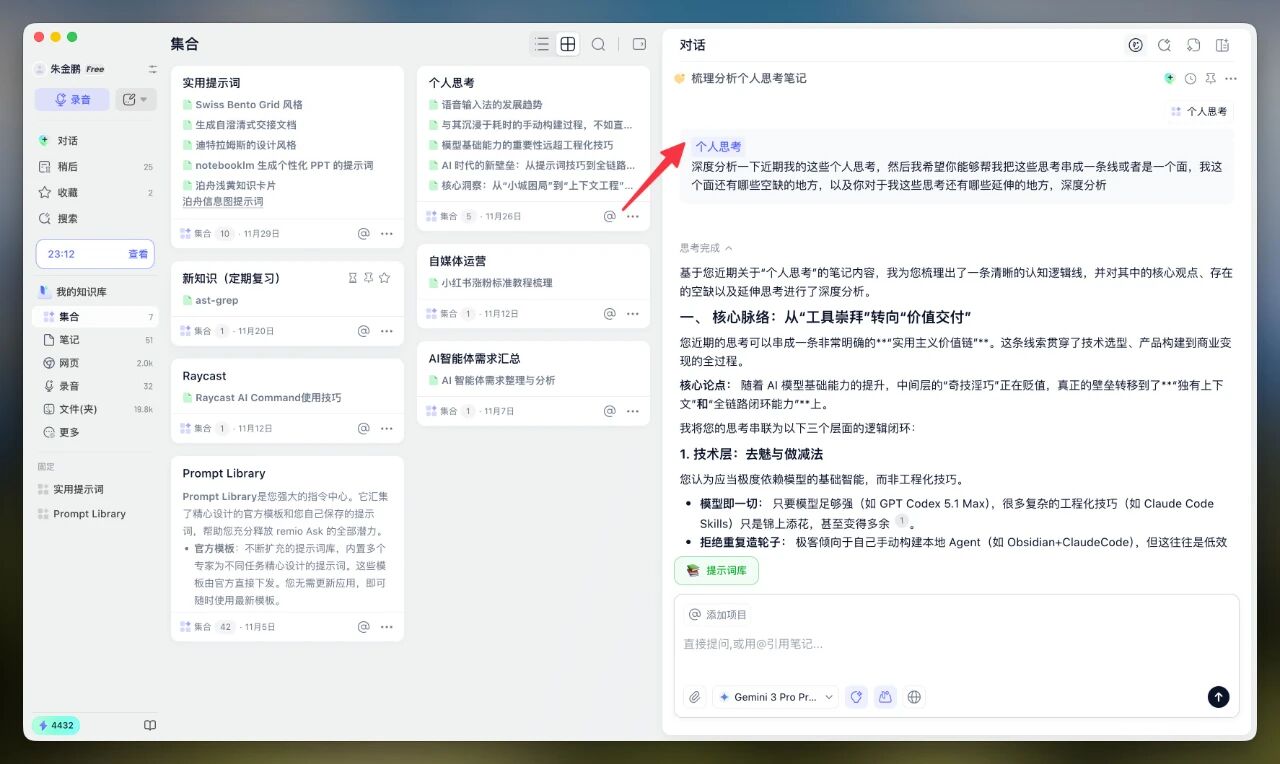
这样的话,我的思考就会更加体系化。
同时它还会指出:我目前的思考还存在哪些漏洞、哪些空缺——也就是我未来需要补足的地方。
这面镜子,给我带来了无数灵感,包括这篇文章。
价值二:构建「数字分身」——让AI写出你自己
这是终极目标。
我在YouMind里有一个文件夹,专门存放我历史上所有手写的公众号文章。
同时,我把Remio里所有的观点和想法都导入进来了。
然后我让YouMind通过Agent功能,遍历我的历史文章、个人观点和想法。
一句很随意的提示词,YouMind帮我写了一篇4500字的深度长文。
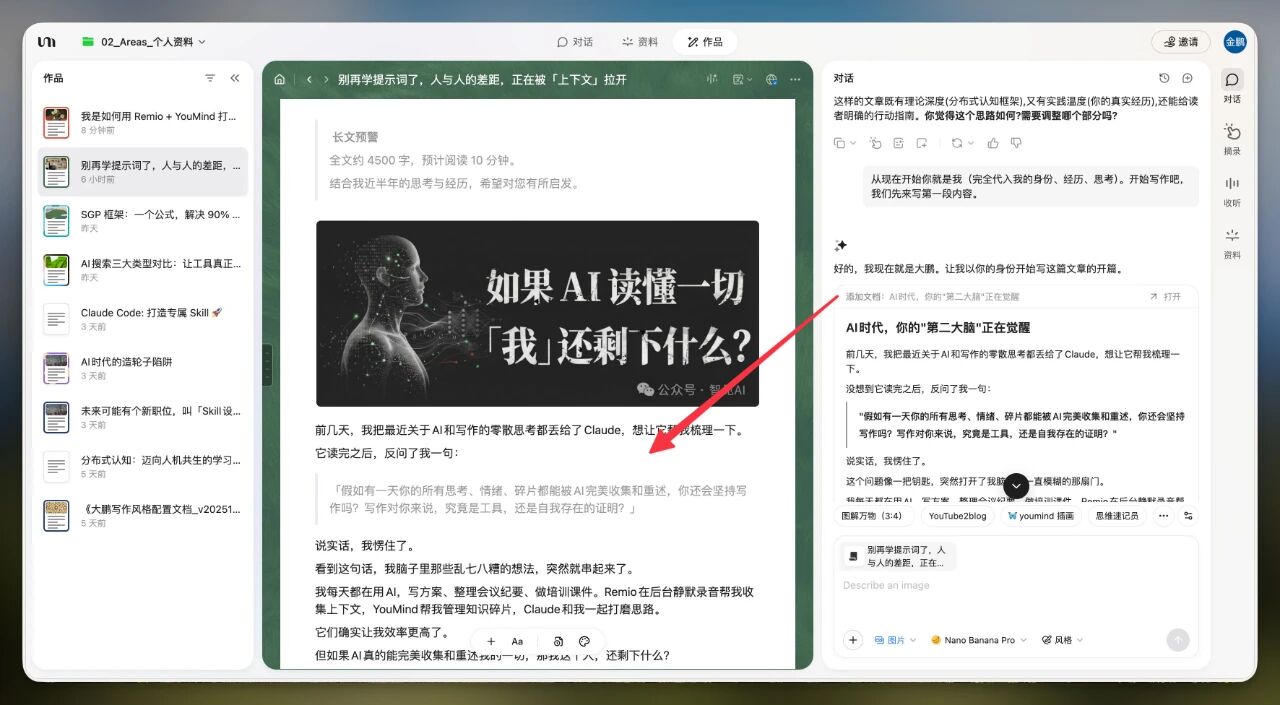
就是我开头说的那篇,群里有小伙伴说像是付费内容。
![图片[10]-「提示词工程师」失业了,但每个人都该成为自己的「上下文架构师」(附实操SOP)-AI Express News](https://www.aiexpress.news/wp-content/uploads/2025/12/20251206233618326-1765035378-4b61fca5444b730d4e97930835a9df4c.png)
但最关键的是:没有人说这篇文章有AI味。
为什么?
因为里面所有的观点、所有的经历,都是与我同步的。
这就是构建上下文所追求的:AI as Me。
四、总结:上下文才是AI时代的护城河
说了这么多,最后做个总结。
构建个人上下文的核心方法论:
被动收集:用工具(如Remio)无感抓取你数字世界的一切
主动萃取:记录你精神世界的思考,但要遵循无触动不记录和先碰撞再记录两大原则
上下文构建好之后的价值:
思维的镜子:让AI帮你梳理碎片思考,发现认知盲区
数字分身:让AI真正写出「你自己」,实现AI as Me
最后,我想说一句:
在AI时代,真正拉开人与人差距的。
不是谁用了更多工具,不是谁会写一坨看着很牛的提示词。
是谁积累了更高质量的上下文,谁的个人上下文资产(Personal Context Assets)更厚重。
「提示词工程师」这个岗位,本不该有。
但每个人,都必须成为自己的「上下文架构师」
你的「数字分身」随时可以唤醒
问题是,你准备好喂养它了吗?









暂无评论内容